Abid Ali Awan 2022-10-27
通过 Python 教程了解最流行的无模型强化学习算法。
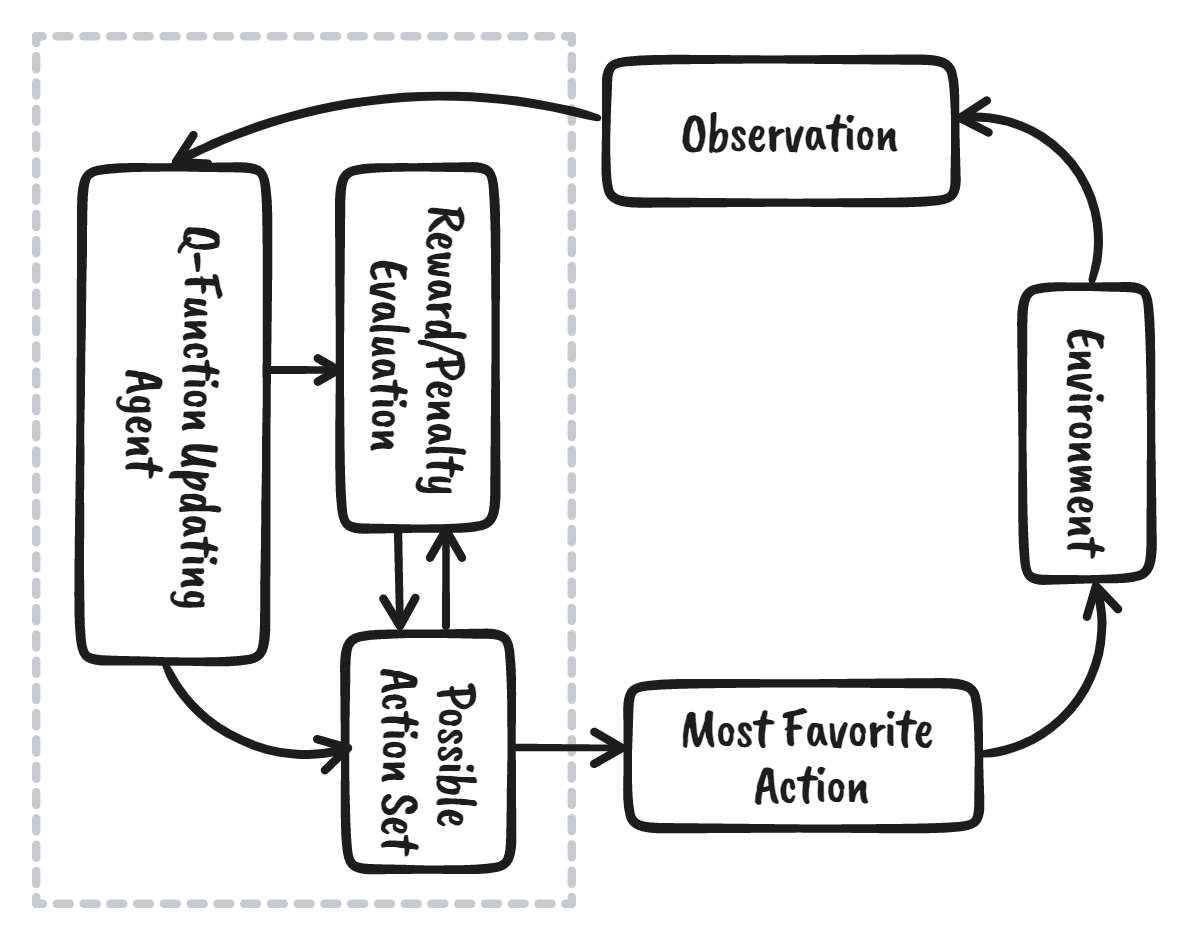
强化学习(Reinforcement Learning, RL)是机器学习生态系统的一部分,其中智能体(agent)通过与环境交互来学习,以获得实现目标的最优策略。它与监督式机器学习算法有很大不同——后者需要我们摄入并处理数据,而强化学习则不需要现成的数据。相反,它通过从环境和奖励系统中学习,以做出更好的决策。
例如,在马里奥(Mario)视频游戏中,如果角色执行一个随机动作(比如向左移动),那么根据该动作,它可能会收到一个奖励。在执行动作后,智能体(马里奥)会进入一个新的状态,这个过程会不断重复,直到游戏角色到达关卡终点或死亡。
这一“回合”(episode)会重复多次,直到马里奥学会通过最大化奖励来导航环境。

我们可以将强化学习分解为五个简单的步骤:
- 智能体处于环境中的初始状态(state zero)。
- 它会根据某种特定策略采取一个动作(action)。
- 根据该动作,它会收到奖励(reward)或惩罚(penalty)。
- 通过从前序动作中学习并优化策略。
- 该过程不断重复,直到找到最优策略。
在本教程中,我们将学习 Q 学习(Q-learning),并理解为何我们需要深度 Q 学习(Deep Q-learning)。此外,我们将使用 NumPy 和 OpenAI Gym 从零开始创建并训练 Q 学习算法。
什么是 Q 学习?
Q 学习是一种无模型(model-free)、基于价值(value-based)、离策略(off-policy)的算法,它能够根据智能体当前的状态,找到最佳的动作序列。“Q”代表“质量”(quality),表示该动作在最大化未来奖励方面的价值。
基于模型(model-based)的算法使用状态转移函数和奖励函数来估计最优策略并构建环境模型;
而无模型(model-free)算法则通过经验直接学习其动作的后果,无需显式的状态转移或奖励函数。
基于价值(value-based)的方法通过训练价值函数,学习哪些状态更有价值,并据此选择动作;
基于策略(policy-based)的方法则直接训练策略,学习在给定状态下应采取哪个动作。
在离策略(off-policy)中,算法评估和更新的策略与用于选择动作的策略不同;
而在同策略(on-policy)中,算法评估并改进的是用于选择动作的同一策略。
Q 学习中的关键术语
在深入探讨 Q 学习如何工作之前,我们需要先了解一些有助于理解 Q 学习基本原理的重要术语:
- 状态(s):智能体在环境中的当前位置。
- 动作(a):智能体在特定状态下所采取的一步操作。
- 奖励(Rewards):对于每个动作,智能体会收到奖励或惩罚。
- 回合(Episodes):阶段的结束,此时智能体无法再采取新动作。当智能体达成目标或失败时即发生。
- Q(St+1, a):在特定状态下执行某个动作的预期最优 Q 值。
- Q(St, At):对 Q(St+1, a) 的当前估计值。
- Q 表(Q-Table):智能体维护的一个包含所有状态-动作对的表格。
- 时序差分(Temporal Differences, TD):利用当前状态和动作以及前一状态和动作,来估计 Q(St+1, a) 的期望值。
Q 学习是如何工作的?
我们将通过“冰湖”(Frozen Lake)的例子详细学习 Q 学习的工作原理。在这个环境中,智能体必须从起点穿越冰湖到达目标点,同时避免掉入洞中。最佳策略是选择最短路径到达目标。

Q 表(Q-Table)
智能体将使用 Q 表,根据每个状态下预期奖励的最大值来选择最佳动作。简而言之,Q 表是一个包含所有状态和动作的数据结构,我们使用 Q 学习算法来更新表中的值。
Q 函数(Q-Function)
Q 函数使用贝尔曼方程(Bellman Equation),以状态(s)和动作(a)作为输入。该方程简化了状态价值和状态-动作价值的计算。
 来源:
来源:Q 学习算法流程
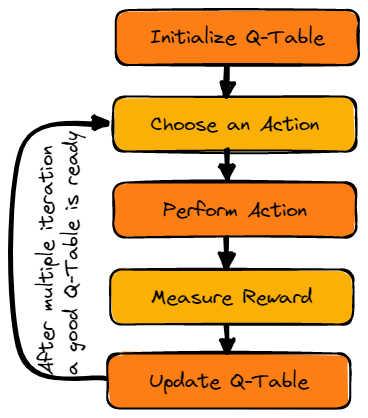
初始化 Q 表
我们首先初始化 Q 表。我们将根据动作数量创建列,根据状态数量创建行。
在我们的例子中,角色可以向上、下、左、右四个方向移动。因此有 4 个可能的动作,以及 4 个状态(起点、空闲、错误路径、终点)。你也可以将“错误路径”视为掉入洞中。我们将 Q 表的所有值初始化为 0。
选择动作
第二步非常简单。一开始,智能体会随机选择一个动作(如下或右);在第二次运行时,它将使用更新后的 Q 表来选择动作。
执行动作
选择动作和执行动作的过程会重复多次,直到训练循环停止。第一次的动作和状态是根据 Q 表选择的。在我们的例子中,Q 表所有值都是 0。
然后,智能体会向下移动,并使用贝尔曼方程更新 Q 表。每次移动后,我们都会更新 Q 表中的值,并用它来决定下一步的最佳行动。
最初,智能体处于探索模式(exploration mode),会随机选择动作以探索环境。ε-贪婪策略(Epsilon Greedy Strategy)是一种平衡探索与利用(exploitation)的简单方法。其中,ε 表示选择探索的概率;当探索概率较小时,智能体就会进行利用。
一开始,ε 值较高,意味着智能体处于探索模式。随着对环境的探索,ε 逐渐减小,智能体开始更多地进行利用。在探索过程中,随着每次迭代,智能体对 Q 值的估计越来越有信心。
在冰湖例子中,智能体一开始不了解环境,因此会随机选择一个动作(比如向下移动)。如上图所示,Q 表已使用贝尔曼方程进行了更新。
衡量奖励
执行动作后,我们将衡量结果和奖励:
- 到达目标的奖励为 +1;
- 走错路径(掉入洞中)的奖励为 0;
- 处于空闲状态或在冰面上移动的奖励也为 0。
更新 Q 表
我们将使用以下公式更新函数 Q(St, At)。该公式使用了上一回合的 Q 值估计、学习率和时序差分误差(TD error)。时序差分误差由即时奖励、折扣后的最大预期未来奖励以及之前的 Q 值估计共同计算得出。
该过程会重复多次,直到 Q 表被充分更新,Q 值函数被最大化。
 方程可视化来自 Thomas Simonini
方程可视化来自 Thomas Simonini
一开始,智能体通过探索环境来更新 Q 表。当 Q 表准备就绪后,智能体将开始利用它,并做出更优的决策。
在冰湖场景中,智能体会学会选择最短路径到达目标,并避免掉入洞中。
Q 学习 Python 教程
在本节中,我们将使用 Gym 环境、Pygame 和 NumPy 从零开始构建 Q 学习模型。本 Python 教程是对 Thomas Simonini 提供的 Notebook 的修改版本,包括:初始化环境和 Q 表、定义贪婪策略、设置超参数、创建并运行训练循环与评估,以及可视化结果。
如果你在创建和运行训练循环时遇到问题,可以查看附带输出的源代码。
环境设置
设置虚拟显示器
我们将首先安装所有依赖项,以便生成回放视频(GIF)。我们需要一个虚拟屏幕(pyvirtualdisplay)来渲染环境并记录帧。
注意:使用
%%capture可以抑制 Jupyter 单元格的输出。
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
安装依赖项
接下来,我们将安装用于创建、运行和评估训练循环的依赖项:
gym:用于初始化 FrozenLake-v1 环境。pygame:用于 FrozenLake-v1 的用户界面。numpy:用于创建和处理 Q 表。
%%capture
!pip install gym==0.24
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpeg
导入包
现在导入所需库:
imageio用于创建动画;tqdm用于进度条。
import numpy as np
import gym
import random
import imageio
from tqdm.notebook import trange
冰湖 Gym 环境
我们将使用 Frozen Lake Gym 库创建一个非滑动(non-slippery)的 4x4 环境。
- 有两种网格版本:“4x4”和“8x8”;
- 如果
is_slippery=True,由于冰面滑动,智能体可能不会按预期方向移动。
初始化环境后,我们将进行环境分析。
env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # 显示一个随机观测
输出:
Observation Space Discrete(16)
Sample observation 15
环境中共有 16 个唯一位置,随机显示。
接下来,我们查看动作数量并显示一个随机动作。
动作空间:
- 0:向左移动
- 1:向下移动
- 2:向右移动
- 3:向上移动
奖励函数:
- 到达目标:+1
- 掉入洞中:0
- 停留在冰面上:0
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())
输出:
Action Space Shape 4
Action Space Sample 1
创建并初始化 Q 表
Q 表的列为动作,行为状态。我们可以使用 OpenAI Gym 获取动作空间和状态空间,然后据此创建 Q 表。
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")
输出:
There are 16 possible states
There are 4 possible actions
初始化 Q 表时,我们将创建一个大小为 state_space × action_space 的 NumPy 数组,即 16×4 的数组。
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)
ε-贪婪策略(Epsilon-greedy policy)
在前文我们已了解 ε-贪婪策略如何平衡探索与利用:
- 以概率
1 - ε进行利用(exploitation):选择当前状态下 Q 值最高的动作; - 以概率
ε进行探索(exploration):随机选择动作。
在 epsilon_greedy_policy 函数中:
- 生成一个 0 到 1 之间的随机数;
- 如果该数大于 ε,则进行利用(选择 Q 值最大的动作);
- 否则进行探索(随机选择动作)。
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return action
定义贪婪策略(Greedy policy)
我们知道 Q 学习是一种离策略算法,这意味着选择动作的策略与更新 Q 函数的策略不同。
在此例中:
- ε-贪婪策略是行为策略(acting policy);
- 贪婪策略是更新策略(updating policy)。
贪婪策略也将是智能体训练完成后的最终策略,用于从 Q 表中选择具有最高状态-动作值的动作。
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return action
模型超参数
这些超参数用于训练循环,微调它们可获得更好结果。
智能体需要充分探索状态空间以学习良好的价值近似,因此我们需要对 ε 进行逐步衰减。如果衰减过快,智能体可能因未充分探索而陷入局部最优。
- 训练回合数:10,000
- 评估回合数:100
- 学习率:0.7
- 环境:
FrozenLake-v1,每回合最多 99 步 - 折扣因子 γ:0.95
- 评估种子:
eval_seed - 初始探索概率 ε:1.0,最小值:0.05
- ε 指数衰减率:0.0005
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005
模型训练
在训练循环中,我们将:
- 遍历所有训练回合;
- 每回合开始时衰减 ε(减少探索,增加利用);
- 重置环境;
- 在最大步数内循环:
- 使用 ε-贪婪策略选择动作;
- 执行动作,观察新状态和奖励;
- 使用贝尔曼方程更新 Q 表;
- 若
done=True,结束当前回合; - 将当前状态更新为新状态;
- 训练结束后返回更新后的 Q 表。
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
state = env.reset()
done = False
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
# Q-learning 更新公式
Qtable[state][action] = Qtable[state][action] + learning_rate * (
reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
)
if done:
break
state = new_state
return Qtable
训练 10,000 个回合仅耗时 3 秒。
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)

训练结果
如你所见,训练后的 Q 表已包含具体数值,智能体现在将利用这些值导航环境并达成目标。
Qtable_frozenlake
输出:
array([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])
评估
evaluate_agent 函数运行 n_eval_episodes 个回合,并返回奖励的均值和标准差。
- 循环中,若提供评估种子,则用该种子重置环境;否则无种子重置;
- 在最大步数内,智能体始终选择 Q 表中当前状态下预期未来奖励最大的动作;
- 累计奖励;
- 若
done(掉入洞中或达成目标),则跳出循环; - 最后计算所有回合奖励的均值和标准差。
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
done = False
total_rewards_ep = 0
for step in range(max_steps):
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_reward
结果完美:100 个评估回合中,智能体每次都成功到达目标。
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")
输出:
Mean_reward=1.00 +/- 0.00
结果可视化
到目前为止,我们一直在处理数字。为了演示,我们需要创建一个从起点到目标的智能体行动 GIF 动画。
- 首先用 0–500 之间的随机整数重置环境;
- 使用
render(mode='rgb_array')渲染图像数组; - 将每帧图像添加到
images列表; - 在循环中,根据 Q 表选择动作并渲染每一步;
- 最后使用
imageio以每秒一帧的速度生成 GIF。
def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action)
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
如果你在 Jupyter Notebook 中,可以使用 IPython.display.Image 显示 GIF:
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')
现在,你可以将这些结果分享给同事、同学,或发布到社交媒体上!