Gurjinder Kaur 2024-11-12
在本文中,我们将学习梯度提升(Gradient Boosting)——一种奠定了XGBoost和LightGBM等流行框架基础的机器学习算法。这些框架在多个机器学习竞赛中屡获殊荣。
无论你是正在考虑在机器学习中使用集成方法的新手,还是已经精通此道、只是想暂时放下.fit()和.predict(),深入探究其内部机制的老手,这篇文章都非常适合你!
我们将涵盖集成学习的基础知识,并通过一个逐步示例解释梯度提升算法如何进行预测。我们还将探讨梯度下降与梯度提升之间的关系,并弄清楚它们是否存在某种联系。让我们开始吧!
集成学习(Ensemble Learning)
集成学习是指训练并组合多个模型(通常是弱学习器),以创建一个具有更高预测能力的强学习器。实现这一目标的两种主要方式是Bagging和Boosting。
1. Bagging
Bagging(Bootstrap Aggregation 的缩写)包括在从训练数据中有放回地采样(即自助采样法,bootstrap sampling)得到的不同子集上,独立地训练多个弱学习器。最终的预测结果通过对每个模型的个体预测进行平均(用于回归)或投票(用于分类)获得。例如,随机森林(Random Forests)就使用 Bagging 方法,在不同的数据子集上训练多棵决策树。
Bagging 能够降低方差,从而使最终的集成模型更不容易过拟合。
2. Boosting
Boosting 涉及顺序地训练多个模型,使得每个模型都能从前一个模型的错误中学习,从而(希望)不再重复相同的错误。
Boosting 的重点在于降低偏差而非方差,并通过迭代“提升”弱学习器来构建最终模型。
Boosting 最初源于对训练数据集中难以预测样本的关注,这也是 AdaBoost 的核心思想。它根据样本是否被前一个模型误分类来调整样本的权重,然后将这些调整过权重的样本传递给下一个模型,从而降低整体误差。AdaBoost 对噪声数据较为敏感,因为存在将异常值赋予过高权重而导致过拟合的风险。
梯度提升(Gradient Boosting)正是为了克服 AdaBoost 的局限性而提出的。它不再对样本重新加权,而是聚焦于残差误差(即当前模型损失函数的梯度)。每一个新的弱学习器(通常是一棵决策树)都被训练用于最小化这些残差,从而提高整体模型的准确性。接下来,让我们深入探讨其工作原理。
梯度提升(Gradient Boosting)
梯度提升是一种机器学习技术,它通过顺序地构建多个弱学习器(通常是决策树)的强集成模型。具体做法是:让一个新的弱学习器去拟合前一个弱学习器所产生的残差误差(即实际值与预测值之间的差异)。
在梯度提升中,每个模型都会修正前一个模型的错误,以最小化某个损失函数——例如回归任务中的均方误差(Mean Squared Error, MSE)或分类任务中的对数损失(Log Loss)。每个模型的预测结果会乘以一个**学习率(learning rate)**后进行累加,最终形成集成预测。
下面我们来看梯度提升模型所遵循的步骤:
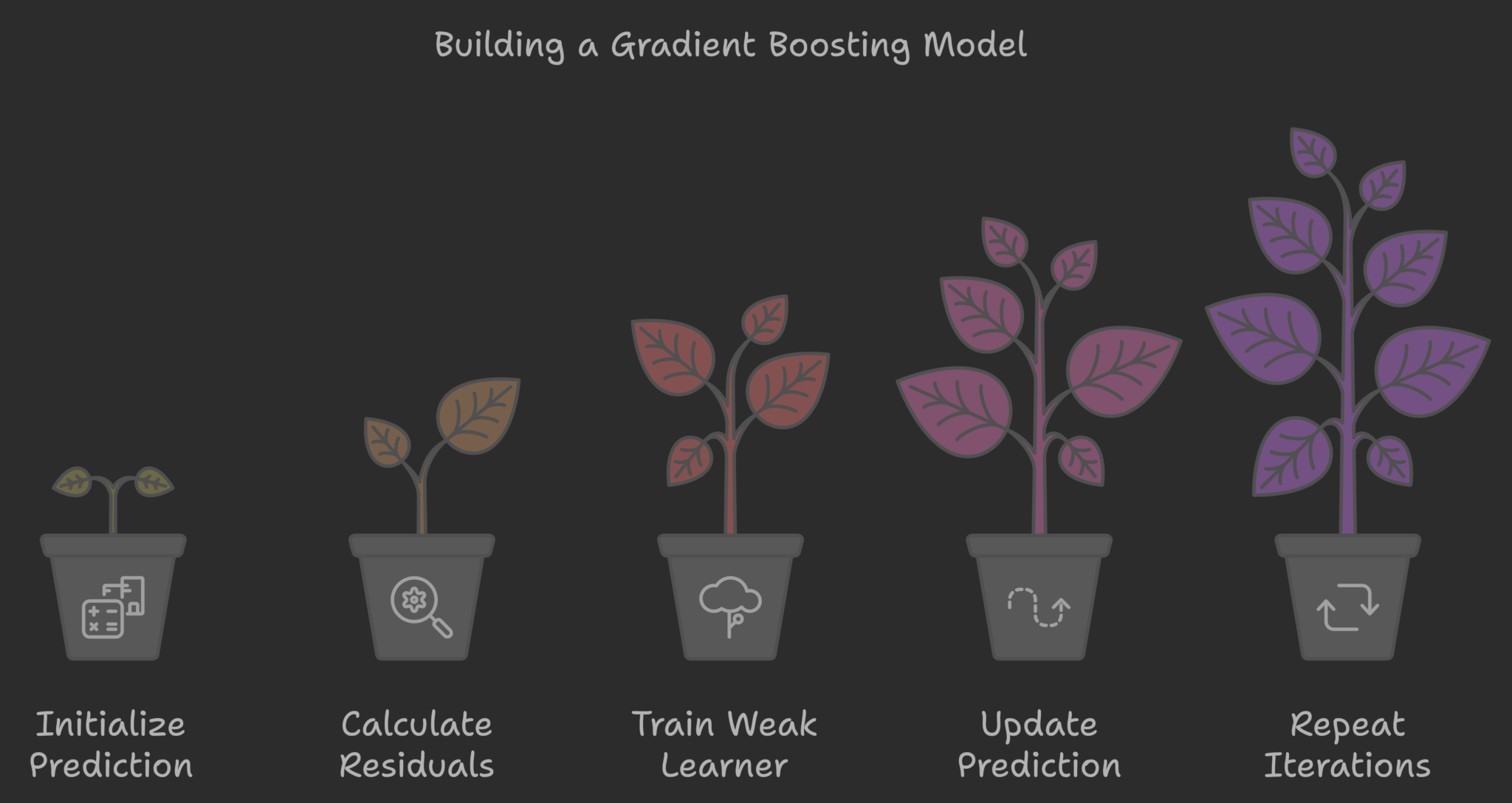 构建梯度提升模型的过程(作者使用 napkin.ai 制作的图像)
构建梯度提升模型的过程(作者使用 napkin.ai 制作的图像)
假设我们要根据房屋面积、房间数量、地段等一系列特征来预测房价,且训练数据中仅有三个样本,如下所示,其中实际价格是我们的目标变量。
 房价预测示例:训练集中包含三个样本(作者绘图)
房价预测示例:训练集中包含三个样本(作者绘图)
步骤 1:初始化预测
在训练任何模型之前,我们首先为所有样本设置一个基线预测值,这通常是训练集中目标变量的平均值。在我们的三套房屋示例中,平均价格为 226,000 美元,因此我们用这个值作为初始预测。
 步骤 1:使用训练数据的平均值初始化基线预测(作者绘图)
步骤 1:使用训练数据的平均值初始化基线预测(作者绘图)
步骤 2:计算残差
在获得每个样本的预测值后,下一步是计算残差,即实际值与预测值之间的差值。这些残差代表了我们基线预测的误差。
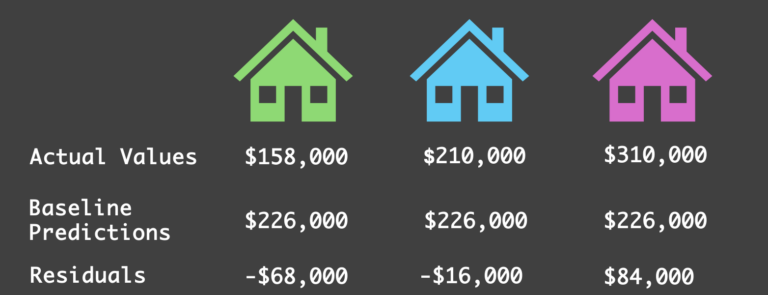 步骤 2:计算残差(作者绘图)
步骤 2:计算残差(作者绘图)
步骤 3:训练弱学习器
在梯度提升中,计算出初始基线预测的残差后,下一步是训练一个弱学习器(例如一棵简单的决策树),但这次的目标不是原始的实际房价,而是上一步计算出的残差。也就是说,决策树的输入是房屋特征,而目标变量是残差(对于第一个模型,使用的是基线预测的残差)。
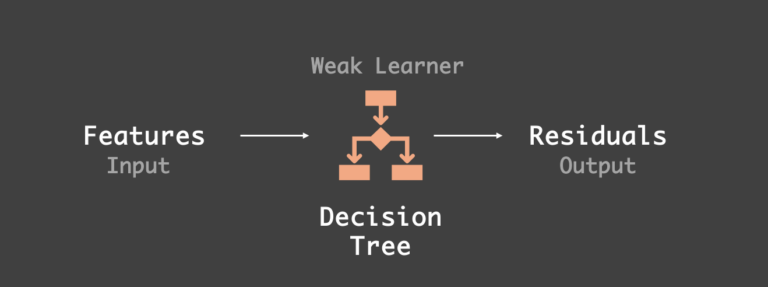 步骤 3:弱学习器被训练用于从输入特征中学习残差(作者绘图)
步骤 3:弱学习器被训练用于从输入特征中学习残差(作者绘图)
假设该弱学习器对三套房屋分别给出了 -50K、-20K 和 +80K 的预测值。注意,这些预测值并不完全等于残差,但旨在降低整体误差——这一点很快就会变得清晰。
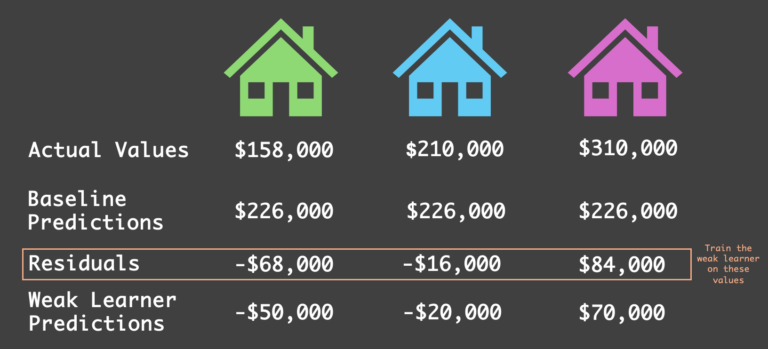 步骤 3:弱学习器对残差的预测被用作误差校正,以更新上一轮的预测(作者绘图)
步骤 3:弱学习器对残差的预测被用作误差校正,以更新上一轮的预测(作者绘图)
弱学习器对残差的预测实际上就是我们的误差校正项——它代表了下一轮预测中需要进行的调整。
步骤 4:更新预测
在弱学习器被训练用于预测残差之后,我们通过将弱学习器的预测(即误差校正)乘以一个 学习率(α表示) 后加到基线预测上,从而更新预测值。学习率是一个关键的超参数,用于控制每个弱学习器对整体模型的贡献程度。
在此例中,我们假设学习率为 0.1。每轮迭代的通用更新规则如下:
其中 表示预测值。利用该规则,我们更新每套房屋的预测值:
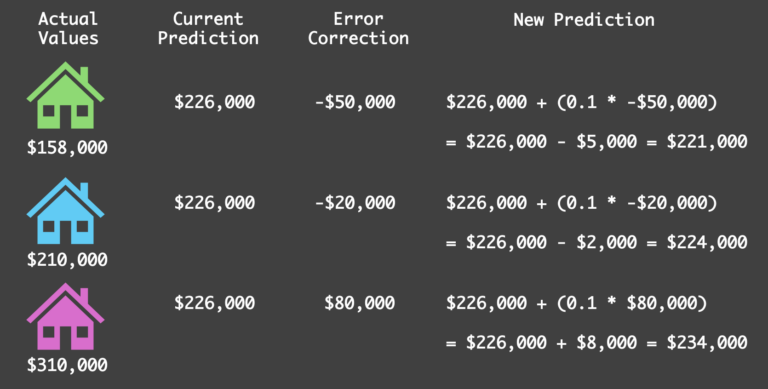 步骤 4:说明如何使用弱学习器对残差的估计(经学习率缩放后)来更新当前预测(作者绘图)
步骤 4:说明如何使用弱学习器对残差的估计(经学习率缩放后)来更新当前预测(作者绘图)
可以看到,每套房屋的预测值都因弱学习器提供的缩放校正而略微更接近实际价格。这体现了学习率在控制每次调整幅度方面的重要作用。
学习率如何影响预测?
- 较高的学习率会导致较大的更新,可能导致“超调”(overshooting)实际值,使模型在收敛过程中出现震荡而非平稳下降。
- 而过低的学习率只会带来微小的调整,需要更多迭代次数才能达到准确预测,可能拖慢学习过程。
步骤 5:重复该过程
在使用第一个弱学习器更新预测后,我们重复步骤 2 至 4,进行多轮迭代。这包括:重新计算残差、在新残差上训练另一个弱学习器,并使用上述更新规则修正上一轮的预测。每轮迭代都会进一步优化模型,使预测值越来越接近真实值。
当然,重复过程并不意味着无限进行下去!我们需要在某个时刻停止,这一决策可基于以下几种因素:
- 固定迭代次数/估计器数量:通常我们会预先设定一个迭代次数作为超参数(例如
n_estimators),决定进行多少轮提升。每轮训练一个新弱学习器,专注于修正前一轮留下的残差误差。 - 误差阈值:当残差或整体误差降到足够小时,表明预测已非常接近真实值,即可停止训练。
- 无显著改进:另一种常见停止条件是当模型在验证集上的性能不再提升时。这有助于避免过拟合,防止模型变得过于复杂。
推理阶段!当我们想预测一套全新房屋的价格时会发生什么?
假设我们在模型中训练了 5 个弱学习器(实际上,这个数量是一个超参数,在使用 scikit-learn 的 GradientBoostingRegressor 时通过 n_estimators 设置)。当一套新房屋出现、我们不知道其价格时,梯度提升模型会从基线预测开始——通常是训练数据中的平均房价。
接着,我们将这套新房屋依次传入所有已训练好的弱学习器(按训练顺序)。每个学习器都从数据中学到了独特的模式,因此它们会逐个添加自己微小的校正项,最终得到一个完整的预测价格!
下图展示了我们刚才讨论的过程:
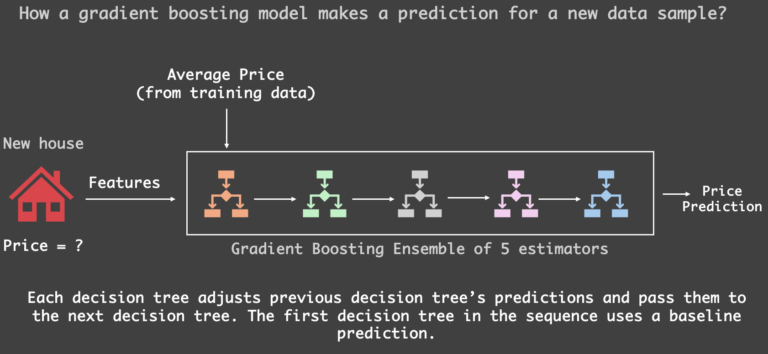 梯度提升模型如何进行预测:数据样本依次通过一系列已训练的弱学习器,得到最终预测(作者绘图)
梯度提升模型如何进行预测:数据样本依次通过一系列已训练的弱学习器,得到最终预测(作者绘图)
梯度提升与梯度下降有关系吗?
你可能会疑惑:梯度下降(Gradient Descent)和梯度提升(Gradient Boosting)之间是否存在联系? 🤔
我认为它们就像“远房表亲”——肯定不是同一个东西,但确实有相似之处。两者的核心思想都是通过迭代向减少误差的方向移动,但它们用途完全不同。
它们的联系在于:都利用梯度来确定减少某个损失函数的方向。
什么是梯度?
梯度是我们在训练机器学习模型时所优化的损失函数的导数。
- 在梯度下降中,我们计算损失函数对模型参数(如权重或系数)的导数。
- 在梯度提升中,我们计算损失函数对预测值的导数。
梯度下降是一种通用的优化算法,它通过迭代更新机器学习模型的参数来最小化损失函数。它计算损失函数相对于参数的梯度(导数),然后沿梯度的反方向更新参数。
而梯度提升则是一种模型集成方法,其中序列中的新模型被拟合到损失函数的负梯度上——这个方向正是能降低整体损失的方向。
在梯度提升中,均方误差(MSE) 是回归任务中最常见且默认的损失函数,其梯度恰好就是残差(即实际值与预测值之差)。
设 为实际值,$\hat{y}$ 为预测值,则均方误差(MSE)损失函数定义为:
对预测值 求导得到梯度:
由于我们希望最小化损失函数,因此应沿梯度的反方向移动,即取负梯度:
这正好就是残差(actual – prediction),我们在前面的房价预测示例中正是使用这个值来调整预测的。
残差和梯度是同一个东西吗?
是,也不是。
- 对于回归任务中的均方误差,残差与负梯度直接成正比,因此它们看起来非常相似。
- 但对于其他损失函数(如分类中的对数损失),梯度可能与残差不同。
- 在梯度提升中,梯度本质上是损失函数对预测值的导数。
结论
在本文中,我们学习了集成学习的基础知识,并深入剖析了梯度提升算法的内在机制。这是一种强大而简洁的机器学习技术,为 XGBoost、LightGBM 和 CatBoost 等多个强大框架奠定了基础。这些库因其高度优化和可扩展性而被广泛应用于各个领域,尤其适合处理大规模数据集,并支持训练数百甚至数千个模型以构建强大的集成系统。
感谢阅读!希望你发现这篇关于梯度提升——这一简单却强大的机器学习技术——的介绍既富有信息量又极具价值。