Kurtis Pykes 2025-01-15
数据的质量直接影响分析结果的准确性和模型性能。为什么?因为原始数据通常包含不一致、错误和无关信息,这些都会扭曲结果并导致错误的洞察。数据预处理正是解决这一问题的有效手段。具体来说,它是将原始数据转换为干净、结构化格式的过程。
在本篇博客文章中,我将涵盖以下内容:
- 什么是数据预处理?
- 数据预处理的步骤
- 数据预处理技术及示例
- 数据预处理工具
- 数据预处理的最佳实践
让我们开始吧!
什么是数据预处理?
数据预处理是数据准备的关键环节。它指的是对原始数据应用的任何处理操作,以使其准备好用于进一步的分析或处理任务。
传统上,数据预处理一直是数据分析中必不可少的初步步骤。然而,近年来,这些技术已被广泛应用于训练机器学习和人工智能(AI)模型,并从中进行推理。
因此,数据预处理可以定义为将原始数据转换为一种更适合高效、准确执行以下任务的格式的过程:
- 数据分析
- 机器学习
- 数据科学
- 人工智能(AI)
数据预处理的步骤
数据预处理涉及多个步骤,每个步骤都针对数据质量、结构和相关性方面的特定挑战。
让我们依次看看这些关键步骤:
步骤 1:数据清洗(Data Cleaning)
数据清洗是指识别并纠正数据中的错误或不一致之处,以确保数据准确且完整。其目标是解决可能扭曲分析结果或模型性能的问题。
例如:
- 处理缺失值:使用均值/众数插补、删除或预测模型等策略来填补或移除缺失数据。
- 去除重复项:消除重复记录,以确保每条记录都是唯一且相关的。
- 修正格式不一致:标准化格式(如日期格式、字符串大小写),以保持一致性。
以下是 Python 中的实现方式:
# 创建一个手动数据集
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# 对 'age' 和 'purchase_amount' 使用均值插补处理缺失值
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# 删除重复行
data = data.drop_duplicates()
# 修正不一致的日期格式
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)

步骤 2:数据集成(Data Integration)
数据集成是指将来自多个来源的数据合并成一个统一的数据集。当数据从不同源系统收集时,这通常是必要的。
数据集成中常用的一些技术包括:
- 模式匹配(Schema matching):对齐不同来源的字段和数据结构,以确保一致性。
- 数据去重(Data deduplication):识别并移除跨多个数据集的重复条目。
例如,假设我们有来自多个数据库的客户数据。以下是将其合并为单一视图的方法:
# 创建两个手动数据集
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# 基于公共键 'customer_id' 合并数据集
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)

步骤 3:数据变换(Data Transformation)
数据变换是将数据转换为适合分析、机器学习或数据挖掘的格式。
例如:
- 缩放与归一化(Scaling and normalization):将数值调整到统一尺度,这对依赖距离度量的算法(如 KNN、SVM)尤为重要。
- 分类变量编码(Encoding categorical variables):使用独热编码(One-hot encoding)或标签编码(Label encoding)等技术将分类数据转换为数值形式。
- 特征工程与提取(Feature engineering and extraction):创建新特征或选择重要特征,以提升模型性能。
以下是使用 scikit-learn 在 Python 中的实现方式:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# 创建一个手动数据集
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# 缩放数值数据
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# 使用独热编码对分类变量进行编码
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# 将编码后的数据与原始数据集拼接
data = pd.concat([data, encoded_data], axis=1)
print(data)
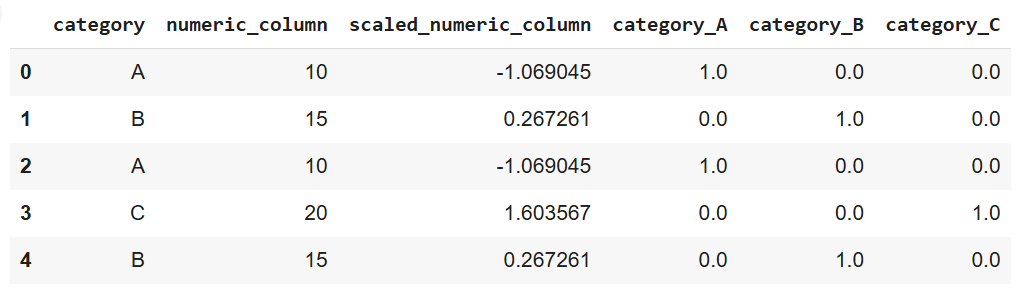
步骤 4:数据规约(Data Reduction)
数据规约通过减少特征数量或记录数量来简化数据集,同时保留关键信息。这有助于加快分析和模型训练速度,而不会牺牲准确性。
数据规约的技术包括:
- 特征选择(Feature selection):选择对分析或模型性能贡献最大的特征。
- 主成分分析(PCA):一种降维技术,将数据转换到低维空间。
- 采样方法(Sampling methods):通过选择代表性样本减少数据集规模,适用于处理大型数据集。
以下是 Python 中实现降维的方式:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# 创建一个手动数据集
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# 使用 SelectKBest 进行特征选择
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# 打印所选特征
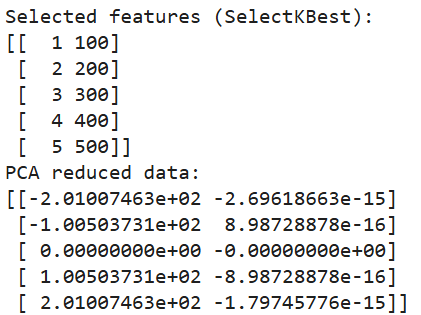
print("Selected features (SelectKBest):")
print(selected_features)
# 使用 PCA 进行降维
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# 打印 PCA 结果
print("PCA reduced data:")
print(pca_data)
常见的数据预处理技术及示例
我们已经明确,预处理原始数据对于确保其适用于分析或机器学习模型至关重要。我们也已介绍了该过程所涉及的步骤。
在本节中,我们将探讨在预处理阶段处理常见问题的各种技术。此外,我们还将介绍数据增强(Data Augmentation)——一种在特定场景(如图像或文本数据集)中创建合成数据的有用技术。
处理缺失数据
缺失数据会对机器学习模型或分析的性能产生负面影响。有多种策略可有效处理缺失值:
- 插补(Imputation):该技术使用计算出的估计值(如可用数据的均值、中位数或众数)填充缺失值。高级方法包括预测建模,即基于数据内部关系预测缺失值。
# 注意:这是示例代码,无法独立运行
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # 可将 'mean' 替换为 'median' 或 'most_frequent'
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])
- 删除(Deletion):移除包含缺失值的行或列是一种直接的解决方案。但应谨慎使用,因为它可能导致有价值数据的丢失,尤其是在大量条目缺失的情况下。
data.dropna(inplace=True) # 移除任何包含缺失值的行
- 对缺失值建模(Modeling missing values):在缺失数据模式较为复杂的情况下,可以使用机器学习模型根据数据集中其他变量的关系来预测缺失值。这可以通过整合变量间的关系来提高准确性。
异常值检测与移除
异常值是显著偏离其余数据的极端值,与缺失值类似,它们也会扭曲分析结果和模型性能。可以使用多种技术来检测和处理异常值:
- Z 分数法(Z-Score method):该方法衡量数据点与均值相差多少个标准差。超过某一阈值(例如 ±3 个标准差)的数据点可被视为异常值。
# 注意:这是示例代码。
# 除非导入了包含名为“column”的列的数据,否则无法运行
from scipy import stats
z_scores = stats.zscore(data['column'])
outliers = abs(z_scores) > 3 # 识别异常值
- 四分位距法(IQR):IQR 是第一四分位数(Q1)与第三四分位数(Q3)之间的范围。低于 Q1 - 1.5 × IQR 或高于 Q3 + 1.5 × IQR 的值被视为异常值。
Q1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))
- 可视化技术(Visual techniques):箱线图、散点图或直方图等可视化方法有助于检测数据集中的异常值。一旦识别出异常值,可根据其对分析的影响选择移除或转换。
数据编码
处理分类数据时,需要进行编码,将类别转换为机器学习算法可处理的数值表示。常见的编码技术包括:
- 独热编码(One-hot encoding):如前所述,该方法为每个类别创建二进制列。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])
- 标签编码(Label encoding):为每个类别分配一个唯一的数值。但如果类别之间没有自然顺序,这种方法可能会引入无意的序数关系。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])
- 序数编码(Ordinal encoding):当分类变量具有固有顺序(如 low、medium、high)时使用。每个类别被映射为反映其排序的整数值。
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])
数据缩放与归一化
缩放和归一化确保数值特征处于相似的尺度,这对于依赖距离度量的算法(如 KNN、SVM)尤为重要。
- 最小-最大缩放(Min-max scaling):将数据缩放到指定范围(通常为 0 到 1)。当所有特征都需要相同尺度时非常有用。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])
- 标准化(Z 分数归一化):该方法将数据缩放,使均值为 0,标准差为 1,有助于模型在正态分布特征上表现更好。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])
数据增强(Data Augmentation)
数据增强是一种通过创建新的合成样本来人为扩大数据集规模的技术。这在深度学习模型中尤其有用,因为图像或文本数据集通常需要大量数据才能获得稳健的模型性能。
- 图像增强(Image augmentation):旋转、翻转、缩放或向图像添加噪声等技术可创建变体,从而提升模型泛化能力。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))
- 文本增强(Text augmentation):对于文本数据,增强方法包括同义词替换、随机插入和回译(back-translation)——即将句子翻译成另一种语言后再翻译回原始语言,从而引入变体。
import nlpaug.augmenter.word as naw
# 在此处安装 nlpaug:https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")
数据预处理工具
虽然你可以使用纯 Python 代码实现数据处理,但已有许多强大的工具被开发出来,用于处理各种任务并使整个过程更高效。以下是一些示例:
Python 库
Python 中有许多专门用于数据预处理的库。以下是三个最流行的:
- Pandas:Python 中最常用的数据操作和清洗库。它提供了灵活的数据结构(主要是 DataFrame 和 Series),使你能够高效地处理和操作结构化数据。Pandas 支持处理缺失数据、合并数据集、过滤数据和重塑数据等操作。
import pandas as pd
# 加载一个示例数据集
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)
- NumPy:用于数值计算的基础库。它支持大型多维数组和矩阵,并提供用于操作这些数组的数学函数。NumPy 通常是许多高级数据处理库(如 Pandas)的基础。
import numpy as np
# 创建一个数组并执行逐元素运算
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)
[ 1 4 9 16 ]
- Scikit-learn:广泛用于机器学习任务,但也提供了众多预处理工具,如缩放、编码和数据变换。其 preprocessing 模块包含处理分类数据、缩放数值数据、特征提取等工具。
from sklearn.preprocessing import StandardScaler
# 标准化数据
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)

云平台
本地系统可能无法有效处理大型数据集。在这种情况下,云平台提供了可扩展、高效的解决方案,使你能够在分布式系统中处理海量数据。
可考虑的一些云平台工具包括:
- AWS Glue:亚马逊网络服务(AWS)提供的全托管 ETL 服务。它能自动发现和组织数据,并为其分析做好准备。Glue 支持数据编目,并可连接到 S3 和 Redshift 等 AWS 服务。
- Azure Data Factory:微软提供的基于云的数据集成服务。它支持构建大规模数据的 ETL 和 ELT 管道。Azure Data Factory 允许用户在各种服务之间移动数据,使用转换对其进行预处理,并通过可视化界面编排工作流。
自动化工具
自动化数据预处理的重复步骤可以节省时间并减少错误——尤其是在处理机器学习模型和大型数据集时。以下是一些提供内置预处理管道的工具:
- AutoML 平台:AutoML 是 Automated Machine Learning(自动化机器学习)的缩写(顾名思义)。换句话说,这些平台可自动完成机器学习工作流的多个阶段。Google AutoML、Microsoft Azure AutoML 和 H2O.ai 的 AutoML 等平台提供自动化管道,可最少人工干预地处理特征选择、数据变换和模型选择等任务。
- scikit-learn 中的预处理管道:Scikit-learn 提供了 Pipeline 类,有助于简化和自动化预处理步骤。它允许你将多个预处理操作串联成一个可执行的工作流,确保预处理任务一致地应用:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# 示例管道:组合不同的预处理任务
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)
数据预处理的最佳实践
为了最大化预处理工作的效果,遵循最佳实践至关重要。以下是我建议你考虑的一些做法:
理解数据
在深入预处理之前,彻底理解数据集非常重要。进行探索性数据分析(EDA),以识别手头数据的结构。你特别需要了解的是:
- 关键特征
- 潜在异常
- 变量间关系
如果不先理解数据集的特性,很可能应用错误的预处理方法,从而扭曲数据。
自动化重复步骤
预处理通常涉及重复性任务。通过构建管道自动化这些任务,可确保一致性和效率,并降低人为错误的概率。利用 scikit-learn 或基于云的平台中的管道来简化工作流。
记录预处理步骤
清晰的文档有助于实现两个目标:
- 可复现性
- 可理解性(无论是为自己日后回顾,还是为团队其他成员)
应记录每一个决策、变换或过滤步骤及其理由。这将极大促进团队协作,并帮助你在中断后顺利继续项目。
迭代式改进
数据预处理不是一次性任务——它应该是一个迭代过程。随着模型不断演进并提供性能反馈,利用这些信息重新审视并优化预处理步骤,往往能带来更好的结果。例如,特征工程可能揭示新的有用特征,或调整异常值处理方式可能提升模型准确性——利用这些反馈更新你的预处理步骤。
结论
数据预处理在任何数据项目的成功中都起着至关重要的作用。适当的预处理可确保原始数据被转换为干净、结构化的格式,从而帮助模型和分析得出更准确、更有意义的洞察。
在本文中,我分享了多种实现数据预处理的技术。但最重要的一点是:这一过程并非一次性努力,而是一个迭代过程!持续优化才能带来模型性能的提升和更优的决策能力。一个经过良好准备的数据集,是任何成功数据与 AI 项目的基石。