Sadrach Pierre 2020-02-13
神经网络是一种受大脑连接方式启发而设计的计算系统。简而言之,神经网络会对输入数据进行一系列变换,这些变换的结果在学习过程中被用作特征。Keras 是一个开源的 Python 库,能够轻松地进行神经网络实验。Keras 提供了神经网络的许多构建模块,包括目标函数、优化器、激活函数、各种类型的层以及大量附加工具。
在本文中,我们将使用 Keras 库构建三个回归神经网络模型。
让我们开始吧!
预测汽车的价值
在第一个示例中,我们将基于客户属性预测一辆汽车可能的销售价值。这些属性包括年龄、收入和性别等信息。相关数据可在此处获取。
首先,我们导入 pandas 并将数据读入一个 DataFrame:
import pandas as pd
df = pd.read_csv("cars.csv")
让我们打印前五行数据:
print(df.head())

接下来,我们将定义输入变量和输出变量。我们将使用“age”(年龄)、“gender”(性别)、“miles”(行驶里程)、“debt”(债务)和“income”(收入)来预测“sales”(销售额):
import numpy as np
X = np.array(df[['age', 'gender', 'miles', 'debt', 'income']])
y = np.array(df['sales'])
现在我们需要将数据划分为训练集和测试集。我们将从 sklearn 导入 train_test_split 方法:
from sklearn.model_selection import train_test_split
然后,我们将测试集定义为随机抽样(占总数据的 20%):
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
接下来,我们需要对标签数组进行重塑:
y_train = np.reshape(y_train, (-1,1))
现在我们可以定义模型了。首先,我们需要导入几个包:
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense
接着,我们定义一个顺序模型对象:
model = Sequential()
让我们构建一个简单的神经网络,包含一个输入层、一个隐藏层和一个输出层。我们将在输入层和隐藏层中使用 ReLU 激活函数,而在输出层使用线性激活函数。输入层和隐藏层都将包含 32 个神经元:
model.add(Dense(32, input_dim=5, kernel_initializer='normal', activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='linear'))
接下来,我们编译模型。我们将使用“adam”优化器和均方误差(MSE)损失函数:
model.compile(loss='mse', optimizer='adam', metrics=['mse','mae'])
最后,我们拟合模型。我们使用 100 个 epoch 和批量大小(batch size)为 10:
model.fit(X_train, y_train, epochs=100, batch_size=10)
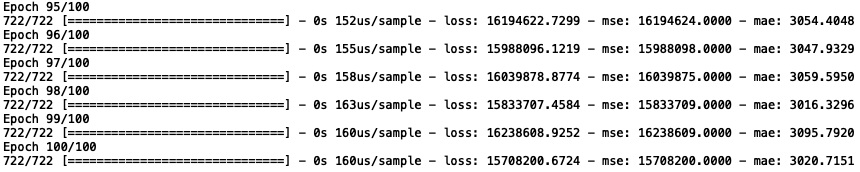
我们可以看到,与销售额的量级相比,均方误差(MSE)和平均绝对误差(MAE)都相当低,这是个不错的信号。
现在,让我们在测试集上进行预测:
y_pred = model.predict(X_test)
接下来,我们可以可视化结果。让我们导入 matplotlib 和 seaborn,并绘制真实值与预测值的散点图:
import matplotlib.pyplot as plt
plt.scatter(y_test, y_pred)
plt.xlabel('True Values')
plt.ylabel('Predictions')
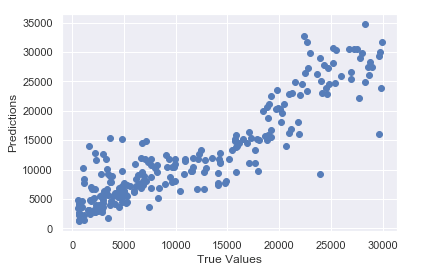
对于初次尝试来说,这样的表现已经相当不错了。通过进一步的超参数调优,我们还能做得更好。为了进一步提升性能,我鼓励你尝试调整层数、神经元数量、epoch 数量以及批量大小。你也可以尝试其他优化器(如“rmsprop”或“sgd”)代替“adam”。此外,你还可以尝试对数据进行归一化、标准化或最小-最大缩放等变换。
预测燃油效率
现在,让我们转向另一个问题。在这个示例中,我们将预测以每加仑英里数(MPG)衡量的燃油效率。我们将使用马力、重量和气缸数量等信息作为预测模型的输入。相关数据可在此处获取。
让我们导入数据并打印前五行:
df = pd.read_csv("auto-mpg.csv")
print(df.head())
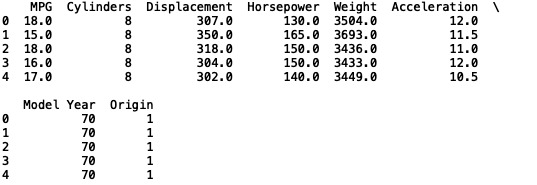
接下来,我们将定义输入和输出变量。我们将使用“Cylinders”(气缸数)、“Displacement”(排量)、“Horsepower”(马力)、“Weight”(重量)、“Acceleration”(加速度)、“Model Year”(车型年份)和“Origin”(产地)来预测每加仑英里数(MPG):
X = np.array(df[['Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']])
y = np.array(df['MPG'])
我们现在需要将数据划分为训练集和测试集。我们将测试集定义为数据的一个随机样本:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
接下来,我们需要对标签数组进行重塑:
y_train = np.reshape(y_train, (-1,1))
现在让我们定义模型。我们从一个具有输入层和隐藏层的神经网络开始,每层包含 64 个神经元。输入维度为 7,优化器为“adam”,损失函数为“mse”。我们还将使用 1000 个 epoch 和批量大小为 10:
model = Sequential()
model.add(Dense(64, input_dim=7, kernel_initializer='normal', activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='linear'))
model.compile(loss='mse', optimizer='adam', metrics=['mse','mae'], validation_split = 0.2)
model.fit(X_train, y_train, epochs=1000, batch_size=10)
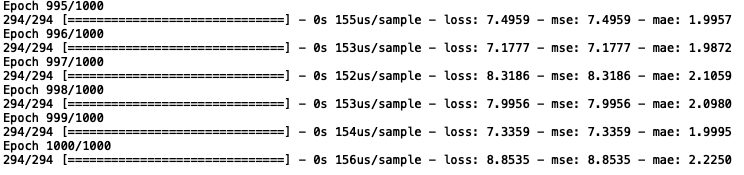
现在,让我们可视化结果:
y_pred = model.predict(X_test)
plt.scatter(y_test, y_pred)
plt.xlabel('True Values')
plt.ylabel('Predictions')
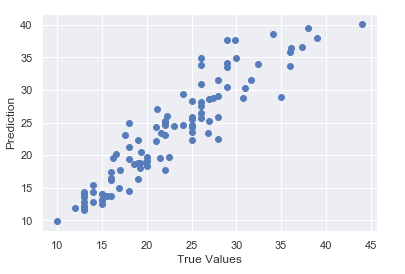
我们可以看到,模型的表现相当不错。我鼓励你尝试进一步提升性能,或者尝试为其他预测问题构建神经网络模型。例如,你可能会对使用美国野火数据,利用神经网络预测野火规模感兴趣。
总结
总而言之,在本文中,我们逐步完成了两个回归问题的建模过程:预测汽车价值和预测燃油效率。我们讨论了如何初始化顺序模型对象、添加层、设置神经元数量、指定优化器、设定 epoch 数量和批量大小。我们还通过真实值与预测值的散点图进行了模型验证。希望你觉得这篇文章有所帮助。本文中的代码可在 GitHub 上获取。感谢阅读,祝你在机器学习的道路上愉快!