Andre Burgaud
Lambda 演算
Python 和其他编程语言中的 Lambda 表达式源于 Lambda 演算(lambda calculus),这是由阿隆佐·丘奇(Alonzo Church)发明的一种计算模型。你将了解到 Lambda 演算何时被提出,以及为何它是一个基础性概念,并最终进入了 Python 生态系统。
历史
阿隆佐·丘奇在 20 世纪 30 年代形式化了 Lambda 演算——一种基于纯粹抽象的语言。Lambda 函数也被称为 Lambda 抽象(lambda abstractions),这直接引用了丘奇原始创造中的抽象模型。
Lambda 演算可以编码任何计算。它是图灵完备的(Turing complete),但与图灵机的概念不同,它是一种纯函数式的模型,不保留任何状态。
函数式语言起源于数理逻辑和 Lambda 演算,而命令式编程语言则采纳了艾伦·图灵(Alan Turing)提出的基于状态的计算模型。这两种计算模型——Lambda 演算和图灵机——可以相互转换。这种等价性被称为 丘奇-图灵假说(Church-Turing hypothesis)。
函数式语言直接继承了 Lambda 演算的哲学,采用了一种声明式的编程方法,强调抽象、数据转换、组合以及纯度(无状态、无副作用)。函数式语言的例子包括 Haskell、Lisp 或 Erlang。
相比之下,图灵机催生了命令式编程,如 Fortran、C 或 Python 中所见。
命令式风格通过语句进行编程,逐步驱动程序流程,提供详细的指令。这种方法鼓励可变性(mutation),并要求管理状态。
这两类语言之间存在一些细微差别:一些函数式语言融入了命令式特性(如 OCaml),而函数式特性也逐渐渗透到命令式语言家族中,特别是 Java 或 Python 引入了 Lambda 函数之后。
Python 本身并不是一种函数式语言,但它很早就采纳了一些函数式概念。1994 年 1 月,map()、filter()、reduce() 以及 lambda 操作符被加入到该语言中。
第一个例子
以下是一些示例,让你初步感受一下 Python 中的函数式风格代码。
恒等函数(identity function)——即返回其参数的函数——可以通过 Python 的标准函数定义方式(使用 def 关键字)如下表示:
>>> def identity(x):
... return x
identity() 接收一个参数 x,并在调用时返回它。
相比之下,如果你使用 Python 的 Lambda 构造,会得到如下形式:
>>> lambda x: x
在上面的例子中,表达式由以下部分组成:
- 关键字:
lambda - 绑定变量(bound variable):
x - 函数体(body):
x
注意:在本文上下文中,“绑定变量”指的是 Lambda 函数的参数。
相比之下,“自由变量”未被绑定,可能在表达式的主体中被引用。自由变量可以是常量,也可以是在函数外部作用域中定义的变量。
你可以编写一个稍复杂一点的例子,比如一个将参数加 1 的函数:
>>> lambda x: x + 1
你可以通过将函数及其参数用括号括起来,来对该函数应用一个参数:
>>> (lambda x: x + 1)(2)
3
归约(Reduction) 是 Lambda 演算中用于计算表达式值的一种策略。在当前示例中,它包括将绑定变量 x 替换为参数 2:
(lambda x: x + 1)(2) = lambda 2: 2 + 1
= 2 + 1
= 3
由于 Lambda 函数是一个表达式,因此它可以被命名。所以你可以将前面的代码写成如下形式:
>>> add_one = lambda x: x + 1
>>> add_one(2)
3
上述 Lambda 函数等价于如下写法:
def add_one(x):
return x + 1
这些函数都只接受一个参数。你可能已经注意到,在 Lambda 定义中,参数周围没有括号。对于多参数函数(即接受多个参数的函数),Python 的 Lambda 通过列出参数并用逗号(,)分隔来表达,但不使用括号包围它们:
>>> full_name = lambda first, last: f'Full name: {first.title()} {last.title()}'
>>> full_name('guido', 'van rossum')
'Full name: Guido Van Rossum'
分配给 full_name 的 Lambda 函数接受两个参数,并返回一个插值了这两个参数 first 和 last 的字符串。正如预期的那样,Lambda 定义中列出参数时不加括号,而调用函数时则像普通 Python 函数一样,使用括号包围参数。
匿名函数
根据编程语言的类型和文化背景,以下术语可能可以互换使用:
- 匿名函数(Anonymous functions)
- Lambda 函数(Lambda functions)
- Lambda 表达式(Lambda expressions)
- Lambda 抽象(Lambda abstractions)
- Lambda 形式(Lambda form)
- 函数字面量(Function literals)
在本文本节之后的部分,你将主要看到“Lambda 函数”这一术语。
从字面上看,匿名函数就是没有名字的函数。在 Python 中,匿名函数通过 lambda 关键字创建。更宽泛地说,它可能被赋值也可能不被赋值。考虑一个使用 lambda 定义但未绑定到变量的双参数匿名函数。这个 Lambda 没有被赋予名称:
>>> lambda x, y: x + y
上面的函数定义了一个接受两个参数并返回其和的 Lambda 表达式。
除了告诉你 Python 完全接受这种形式之外,它并没有带来任何实际用途。你可以在 Python 解释器中调用该函数:
>>> _(1, 2)
3
上面的例子利用了交互式解释器独有的特性——通过下划线 _。更多细节请参见下面的注释。
你不能在 Python 模块中编写类似的代码。可以把解释器中的 _ 看作是你利用的一个副作用。在 Python 模块中,你会将 Lambda 赋值给一个名称,或者将 Lambda 传递给一个函数。你将在本文后面使用这两种方法。
注意:在交互式解释器中,单个下划线
_绑定到上一次求值的表达式。
在上面的例子中,_ 指向 Lambda 函数。
另一种在 JavaScript 等语言中常见的模式是立即执行 Python Lambda 函数。这被称为 立即调用函数表达式(IIFE,读作 “iffy”)。示例如下:
>>> (lambda x, y: x + y)(2, 3)
5
上面的 Lambda 函数被定义后立即使用两个参数(2 和 3)调用。它返回值 5,即参数之和。
本教程中的几个示例使用这种格式来突出 Lambda 函数的匿名特性,并避免将 Python 中的 Lambda 仅仅视为定义函数的简写方式。
Python 并不鼓励使用立即调用的 Lambda 表达式。这只是因为 Lambda 表达式本身是可调用的,而普通函数的函数体则不是。
Lambda 函数经常与高阶函数一起使用,高阶函数是指接受一个或多个函数作为参数,或返回一个或多个函数的函数。
Lambda 函数本身也可以是高阶函数,例如通过接受一个函数(普通函数或 Lambda)作为参数,如下所示(这是一个人为构造的例子):
>>> high_ord_func = lambda x, func: x + func(x)
>>> high_ord_func(2, lambda x: x * x)
6
>>> high_ord_func(2, lambda x: x + 3)
7
Python 在内置函数或标准库中提供了高阶函数。例如 map()、filter()、functools.reduce(),以及像 sort()、sorted()、min() 和 max() 这样的关键字函数。你将在“Lambda 表达式的适当用途”一节中将 Lambda 函数与 Python 高阶函数结合使用。
Python Lambda 与常规函数
来自《Python 设计与历史 FAQ》的一段引述似乎为 Python 中 Lambda 函数的使用设定了基调:
与其他语言中的 Lambda 形式不同(它们增加了功能性),Python 的 Lambdas 只是一种简写符号,仅适用于那些懒得定义函数的人。(来源)
尽管如此,不要让这句话阻止你使用 Python 的 Lambda。乍一看,你可能会认为 Lambda 函数只是带有一些语法糖的函数,用于缩短定义或调用函数的代码。接下来的章节将突出常规 Python 函数与 Lambda 函数之间的共性与细微差异。
函数
此时,你可能会疑惑:一个绑定到变量的 Lambda 函数与一个只包含单行 return 语句的常规函数,从根本上有什么区别?事实上,几乎没有什么区别。让我们验证一下 Python 如何看待一个只包含单行 return 的函数与一个作为表达式构建的函数(Lambda)。
dis 模块提供了分析 Python 字节码(由 Python 编译器生成)的函数:
>>> import dis
>>> add = lambda x, y: x + y
>>> type(add)
<class 'function'>
>>> dis.dis(add)
1 0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD
6 RETURN_VALUE
>>> add
<function <lambda> at 0x7f30c6ce9ea0>
你可以看到,dis() 展示了 Python 字节码的可读版本,允许检查 Python 解释器在执行程序时将使用的低级指令。
现在看看一个常规函数对象:
>>> import dis
>>> def add(x, y): return x + y
>>> type(add)
<class 'function'>
>>> dis.dis(add)
1 0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD
6 RETURN_VALUE
>>> add
<function add at 0x7f30c6ce9f28>
Python 为这两个函数生成的字节码是相同的。但你可能会注意到命名不同:使用 def 定义的函数名为 add,而 Python Lambda 函数被显示为 <lambda>。
回溯(Traceback)
在上一节中,你看到在 Lambda 函数的上下文中,Python 没有提供函数名,而只显示 <lambda>。当异常发生时,回溯仅显示 <lambda>,这可能是一个需要考虑的限制:
>>> div_zero = lambda x: x / 0
>>> div_zero(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
ZeroDivisionError: division by zero
当 Lambda 函数执行过程中引发异常时,回溯仅将引发异常的函数标识为 <lambda>。
下面是同一个异常由常规函数引发的情况:
>>> def div_zero(x): return x / 0
>>> div_zero(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in div_zero
ZeroDivisionError: division by zero
常规函数引发的错误类似,但回溯更精确,因为它给出了函数名 div_zero。
语法
如前几节所示,Lambda 形式在语法上与常规函数有所不同。具体来说,Lambda 函数具有以下特点:
- 它只能包含表达式,不能在其主体中包含语句。
- 它被写成一行执行代码。
- 它不支持类型注解。
- 它可以被立即调用(IIFE)。
不能包含语句
Lambda 函数不能包含任何语句。在 Lambda 函数中,像 return、pass、assert 或 raise 这样的语句会引发 SyntaxError 异常。以下是在 Lambda 主体中添加 assert 的示例:
>>> (lambda x: assert x == 2)(2)
File "<input>", line 1
(lambda x: assert x == 2)(2)
^
SyntaxError: invalid syntax
这个人为构造的例子试图断言参数 x 的值为 2。但是,解释器在解析代码时识别出 Lambda 主体中的 assert 语句,从而抛出 SyntaxError。
单一表达式
与常规函数不同,Python Lambda 函数是一个单一表达式。尽管如此,在 Lambda 的主体中,你可以使用括号或多行字符串将表达式分布在多行上,但它仍然是一个单一表达式:
>>> (lambda x:
... (x % 2 and 'odd' or 'even'))(3)
'odd'
上面的例子在 Lambda 参数为奇数时返回字符串 'odd',为偶数时返回 'even'。它跨越两行是因为被包含在括号中,但它仍然是一个单一表达式。
类型注解
如果你已经开始采用类型提示(Python 现已支持),那么你就有另一个充分的理由优先选择常规函数而非 Python Lambda 函数。在 Lambda 函数中,无法实现如下等效功能:
def full_name(first: str, last: str) -> str:
return f'{first.title()} {last.title()}'
任何与 full_name() 相关的类型错误都可以被 mypy 或 pyre 等工具捕获,而等效的 Lambda 函数会在运行时引发 SyntaxError:
>>> lambda first: str, last: str: first.title() + " " + last.title() -> str
File "<stdin>", line 1
lambda first: str, last: str: first.title() + " " + last.title() -> str
SyntaxError: invalid syntax
就像试图在 Lambda 中包含语句一样,添加类型注解也会在运行时立即引发 SyntaxError。
IIFE(立即调用函数表达式)
你已经看过几个立即调用函数执行的例子:
>>> (lambda x: x * x)(3)
9
在 Python 解释器之外,这种特性在实践中可能不会被使用。这是 Lambda 函数在定义时即可调用的直接结果。例如,这允许你将 Python Lambda 表达式的定义传递给高阶函数,如 map()、filter() 或 functools.reduce(),或传递给关键字函数。
参数
与使用 def 定义的常规函数对象一样,Python Lambda 表达式支持所有不同的参数传递方式。这包括:
- 位置参数(Positional arguments)
- 命名参数(有时称为关键字参数,Named/keyword arguments)
- 可变参数列表(通常称为 varargs)
- 可变关键字参数列表(Variable list of keyword arguments)
- 仅限关键字参数(Keyword-only arguments)
以下示例说明了你可以用来向 Lambda 表达式传递参数的选项:
>>> (lambda x, y, z: x + y + z)(1, 2, 3)
6
>>> (lambda x, y, z=3: x + y + z)(1, 2)
6
>>> (lambda x, y, z=3: x + y + z)(1, y=2)
6
>>> (lambda *args: sum(args))(1,2,3)
6
>>> (lambda **kwargs: sum(kwargs.values()))(one=1, two=2, three=3)
6
>>> (lambda x, *, y=0, z=0: x + y + z)(1, y=2, z=3)
6
装饰器
在 Python 中,装饰器是一种允许向函数或类添加行为的模式。它通常以前缀 @decorator 语法表示。以下是一个人为构造的例子:
def some_decorator(f):
def wraps(*args):
print(f"Calling function '{f.__name__}'")
return f(args)
return wraps
@some_decorator
def decorated_function(x):
print(f"With argument '{x}'")
在上面的例子中,some_decorator() 是一个函数,它为 decorated_function() 添加了行为,因此调用 decorated_function("Python") 会产生以下输出:
Calling function 'decorated_function'
With argument 'Python'
decorated_function() 本身只打印 With argument 'Python',但装饰器额外添加了打印 Calling function 'decorated_function' 的行为。
装饰器可以应用于 Lambda。虽然不能使用 @decorator 语法装饰 Lambda,但装饰器本身只是一个函数,因此它可以调用 Lambda 函数:
# 定义一个装饰器
def trace(f):
def wrap(*args, **kwargs):
print(f"[TRACE] func: {f.__name__}, args: {args}, kwargs: {kwargs}")
return f(*args, **kwargs)
return wrap
# 将装饰器应用于函数
@trace
def add_two(x):
return x + 2
# 调用被装饰的函数
add_two(3)
# 将装饰器应用于 Lambda
print((trace(lambda x: x ** 2))(3))
在第 11 行,用 @trace 装饰的 add_two() 在第 15 行以参数 3 调用。相比之下,在第 18 行,Lambda 函数被立即调用并嵌入到对 trace()(装饰器)的调用中。执行上述代码时,你会得到以下结果:
[TRACE] func: add_two, args: (3,), kwargs: {}
[TRACE] func: <lambda>, args: (3,), kwargs: {}
9
可以看到,正如你之前所见,Lambda 函数的名称显示为 <lambda>,而普通函数 add_two 则被明确标识。
以这种方式装饰 Lambda 函数可能对调试有用,尤其是在高阶函数或关键字函数上下文中调试 Lambda 函数的行为。以下是一个与 map() 结合使用的示例:
list(map(trace(lambda x: x*2), range(3)))
map() 的第一个参数是一个将参数乘以 2 的 Lambda。该 Lambda 被 trace() 装饰。执行上述示例时,输出如下:
[TRACE] Calling <lambda> with args (0,) and kwargs {}
[TRACE] Calling <lambda> with args (1,) and kwargs {}
[TRACE] Calling <lambda> with args (2,) and kwargs {}
[0, 2, 4]
结果 [0, 2, 4] 是通过将 range(3) 中的每个元素乘以 2 得到的列表。目前,你可以将 range(3) 视为等同于列表 [0, 1, 2]。
你将在“Map”一节中更详细地了解 map()。
Lambda 本身也可以作为装饰器,但不推荐这样做。如果你发现自己需要这样做,请参考 PEP 8,编程建议。
闭包(Closure)
闭包是一个函数,其中使用的所有自由变量(即除参数外的所有内容)都绑定到其封闭作用域中定义的特定值。实际上,闭包定义了其运行的环境,因此可以从任何地方调用。
Lambda 和闭包的概念不一定相关,尽管 Lambda 函数可以像普通函数一样成为闭包。某些语言为闭包或 Lambda 提供了特殊构造(例如 Groovy 中的匿名代码块作为 Closure 对象,或 Java Lambda 表达式对闭包的有限支持)。
以下是一个使用普通 Python 函数构造的闭包:
def outer_func(x):
y = 4
def inner_func(z):
print(f"x = {x}, y = {y}, z = {z}")
return x + y + z
return inner_func
for i in range(3):
closure = outer_func(i)
print(f"closure({i+5}) = {closure(i+5)}")
outer_func() 返回 inner_func(),这是一个计算三个参数之和的嵌套函数:
x作为参数传递给outer_func()。y是outer_func()的局部变量。z是传递给inner_func()的参数。
为了测试 outer_func() 和 inner_func() 的行为,在 for 循环中调用了三次 outer_func(),打印如下内容:
x = 0, y = 4, z = 5
closure(5) = 9
x = 1, y = 4, z = 6
closure(6) = 11
x = 2, y = 4, z = 7
closure(7) = 13
在代码第 9 行,由 outer_func() 调用返回的 inner_func() 被绑定到名称 closure。在第 5 行,inner_func() 捕获了 x 和 y,因为它可以访问其嵌入环境,因此在调用闭包时,它能够操作这两个自由变量 x 和 y。
同样,Lambda 也可以是闭包。以下是使用 Python Lambda 函数的相同示例:
def outer_func(x):
y = 4
return lambda z: x + y + z
for i in range(3):
closure = outer_func(i)
print(f"closure({i+5}) = {closure(i+5)}")
执行上述代码时,你会得到以下输出:
closure(5) = 9
closure(6) = 11
closure(7) = 13
在第 6 行,outer_func() 返回一个 Lambda 并将其分配给变量 closure。在第 3 行,Lambda 函数的主体引用了 x 和 y。变量 y 在定义时可用,而 x 在运行时定义(当调用 outer_func() 时)。
在这种情况下,普通函数和 Lambda 表现相似。在下一节中,你将看到一种情况,Lambda 的行为可能具有欺骗性,这是由于其求值时间(定义时 vs 运行时)造成的。
求值时间
在涉及循环的某些情况下,Python Lambda 函数作为闭包的行为可能违反直觉。这需要理解自由变量在 Lambda 上下文中何时被绑定。以下示例展示了使用常规函数与使用 Python Lambda 时的差异。
首先使用常规函数测试该场景:
>>> def wrap(n):
... def f():
... print(n)
... return f
...
>>> numbers = 'one', 'two', 'three'
>>> funcs = []
>>> for n in numbers:
... funcs.append(wrap(n))
...
>>> for f in funcs:
... f()
...
one
two
three
在常规函数中,n 在定义时(第 9 行,当函数被添加到列表时:funcs.append(wrap(n)))被求值。
现在,使用 Lambda 函数实现相同逻辑,观察意外行为:
>>> numbers = 'one', 'two', 'three'
>>> funcs = []
>>> for n in numbers:
... funcs.append(lambda: print(n))
...
>>> for f in funcs:
... f()
...
three
three
three
意外结果的发生是因为在此实现中,自由变量 n 在 Lambda 表达式的执行时被绑定。第 4 行的 Python Lambda 函数是一个闭包,它捕获了 n,这是一个在运行时绑定的自由变量。在第 7 行调用函数 f 时,n 的值已经是 three。
要解决此问题,你可以在定义时分配自由变量,如下所示:
>>> numbers = 'one', 'two', 'three'
>>> funcs = []
>>> for n in numbers:
... funcs.append(lambda n=n: print(n))
...
>>> for f in funcs:
... f()
...
one
two
three
Python Lambda 函数在参数方面表现得像普通函数。因此,Lambda 参数可以用默认值初始化:参数 n 将外部的 n 作为默认值。Python Lambda 函数也可以写成 lambda x=n: print(x),结果相同。
第 7 行调用 Python Lambda 函数时没有传入任何参数,它使用了在定义时设置的默认值 n。
测试 Lambda
Python Lambda 可以像常规函数一样进行测试。可以使用 unittest 和 doctest。
unittest
unittest 模块以与常规函数类似的方式处理 Python Lambda 函数:
import unittest
addtwo = lambda x: x + 2
class LambdaTest(unittest.TestCase):
def test_add_two(self):
self.assertEqual(addtwo(2), 4)
def test_add_two_point_two(self):
self.assertEqual(addtwo(2.2), 4.2)
def test_add_three(self):
# 应该失败
self.assertEqual(addtwo(3), 6)
if __name__ == '__main__':
unittest.main(verbosity=2)
LambdaTest 定义了一个测试用例,包含三个测试方法,每个方法都对作为 Lambda 函数实现的 addtwo() 进行测试。执行包含 LambdaTest 的 Python 文件 lambda_unittest.py 会产生以下结果:
$ python lambda_unittest.py
test_add_three (__main__.LambdaTest) ... FAIL
test_add_two (__main__.LambdaTest) ... ok
test_add_two_point_two (__main__.LambdaTest) ... ok
======================================================================
FAIL: test_add_three (__main__.LambdaTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "lambda_unittest.py", line 18, in test_add_three
self.assertEqual(addtwo(3), 6)
AssertionError: 5 != 6
----------------------------------------------------------------------
Ran 3 tests in 0.001s
FAILED (failures=1)
正如预期,我们有两个成功的测试用例和一个失败的 test_add_three:结果是 5,但预期结果是 6。这个失败是由于测试用例中故意犯的错误。将预期结果从 6 改为 5 将满足 LambdaTest 的所有测试。
doctest
doctest 模块从文档字符串中提取交互式 Python 代码以执行测试。尽管 Python Lambda 函数的语法不支持典型的文档字符串,但可以将字符串分配给命名 Lambda 的 __doc__ 元素:
addtwo = lambda x: x + 2
addtwo.__doc__ = """Add 2 to a number.
>>> addtwo(2)
4
>>> addtwo(2.2)
4.2
>>> addtwo(3) # Should fail
6
"""
if __name__ == '__main__':
import doctest
doctest.testmod(verbose=True)
Lambda addtwo() 的文档字符串中的 doctest 描述了与上一节相同的测试用例。
当你通过 doctest.testmod() 执行测试时,会得到以下结果:
$ python lambda_doctest.py
Trying:
addtwo(2)
Expecting:
4
ok
Trying:
addtwo(2.2)
Expecting:
4.2
ok
Trying:
addtwo(3) # Should fail
Expecting:
6
**********************************************************************
File "lambda_doctest.py", line 16, in __main__.addtwo
Failed example:
addtwo(3) # Should fail
Expected:
6
Got:
5
1 items had no tests:
__main__
**********************************************************************
1 items had failures:
1 of 3 in __main__.addtwo
3 tests in 2 items.
2 passed and 1 failed.
***Test Failed*** 1 failures.
失败的测试源于上一节中单元测试执行时解释的相同失败。
你可以通过将字符串分配给 __doc__ 来为 Python Lambda 添加文档字符串。虽然可行,但 Python 语法更适合为普通函数而非 Lambda 函数提供文档字符串。
Lambda 表达式的滥用
本文中的几个示例,如果写在专业 Python 代码的上下文中,会被视为滥用。
如果你发现自己试图克服 Lambda 表达式不支持的某些功能,这很可能表明使用普通函数更为合适。上一节中 Lambda 表达式的文档字符串就是一个很好的例子。试图克服 Python Lambda 函数不支持语句的事实是另一个危险信号。
接下来的章节将展示一些应避免的 Lambda 用法示例。这些示例可能是 Python Lambda 上下文中代码表现出以下模式的情况:
- 不符合 Python 风格指南(PEP 8)
- 冗长且难以阅读
- 为了显得聪明而牺牲了可读性
引发异常
尝试在 Python Lambda 中引发异常应该让你三思。虽然有一些巧妙的方法可以做到这一点,但即使是以下方法也最好避免:
>>> def throw(ex): raise ex
>>> (lambda: throw(Exception('Something bad happened')))()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
File "<stdin>", line 1, in throw
Exception: Something bad happened
由于语句在 Python Lambda 主体中语法上不正确,上述示例中的变通方法是使用专用函数 throw() 抽象语句调用。应避免使用此类变通方法。如果你遇到此类代码,应考虑重构代码以使用常规函数。
难以理解的风格
如同任何编程语言一样,你会发现一些 Python 代码由于所使用的风格而难以阅读。Lambda 函数由于其简洁性,可能导致编写出难以阅读的代码。
以下 Lambda 示例包含几种不良风格选择:
>>> (lambda _: list(map(lambda _: _ // 2, _)))([1,2,3,4,5,6,7,8,9,10])
[0, 1, 1, 2, 2, 3, 3, 4, 4, 5]
下划线 _ 指的是你不需要显式引用的变量。但在此示例中,三个 _ 指的是不同的变量。对此 Lambda 代码的初步改进可能是为变量命名:
>>> (lambda some_list: list(map(lambda n: n // 2,
some_list)))([1,2,3,4,5,6,7,8,9,10])
[0, 1, 1, 2, 2, 3, 3, 4, 4, 5]
诚然,它仍然难以阅读。通过仍利用 Lambda,一个常规函数将大大增强此代码的可读性,将逻辑分散到几行和函数调用中:
>>> def div_items(some_list):
div_by_two = lambda n: n // 2
return map(div_by_two, some_list)
>>> list(div_items([1,2,3,4,5,6,7,8,9,10])))
[0, 1, 1, 2, 2, 3, 3, 4, 4, 5]
这仍然不是最优的,但它为你展示了一条可能的路径,使代码(尤其是 Python Lambda 函数)更具可读性。在“Lambda 的替代方案”一节中,你将学习如何用列表推导式或生成器表达式替换 map() 和 Lambda。这将极大地提高代码的可读性。
Python 类
你可以但不应该将类方法编写为 Python Lambda 函数。以下示例是完全合法的 Python 代码,但展示了依赖 Lambda 的非传统 Python 代码。例如,__str__ 没有实现为常规函数,而是使用了 Lambda。同样,brand 和 year 也是使用 Lambda 函数实现的属性,而不是常规函数或装饰器:
class Car:
"""Car with methods as lambda functions."""
def __init__(self, brand, year):
self.brand = brand
self.year = year
brand = property(lambda self: getattr(self, '_brand'),
lambda self, value: setattr(self, '_brand', value))
year = property(lambda self: getattr(self, '_year'),
lambda self, value: setattr(self, '_year', value))
__str__ = lambda self: f'{self.brand} {self.year}' # 1: error E731
honk = lambda self: print('Honk!') # 2: error E731
运行像 flake8 这样的风格指南强制工具将为 __str__ 和 honk 显示以下错误:
E731 do not assign a lambda expression, use a def
尽管 flake8 没有指出属性中使用 Python Lambda 函数的问题,但它们难以阅读,并且由于使用了多个字符串(如 '_brand' 和 '_year')而容易出错。
__str__ 的正确实现应如下所示:
def __str__(self):
return f'{self.brand} {self.year}'
brand 应写成如下形式:
@property
def brand(self):
return self._brand
@brand.setter
def brand(self, value):
self._brand = value
作为一般规则,在 Python 编写的代码上下文中,优先选择常规函数而非 Lambda 表达式。尽管如此,在某些情况下,Lambda 语法确实能提供价值,正如你将在下一节中看到的那样。
Lambda 表达式的适当用途
Python 中的 Lambdas 往往是争议的主题。反对 Python 中 Lambdas 的一些论点包括:
- 可读性问题
- 强加函数式思维方式
lambda关键字的语法过于笨重
尽管存在质疑该特性在 Python 中存在的激烈争论,Lambda 函数具有一些有时为 Python 语言和开发者提供价值的特性。
以下示例说明了 Lambda 函数不仅适用而且在 Python 代码中被鼓励使用的场景。
经典函数式构造
Lambda 函数经常与内置函数 map() 和 filter() 以及 functools 模块中的 functools.reduce() 一起使用。以下三个示例分别展示了将这些函数与 Lambda 表达式结合使用的场景:
>>> list(map(lambda x: x.upper(), ['cat', 'dog', 'cow']))
['CAT', 'DOG', 'COW']
>>> list(filter(lambda x: 'o' in x, ['cat', 'dog', 'cow']))
['dog', 'cow']
>>> from functools import reduce
>>> reduce(lambda acc, x: f'{acc} | {x}', ['cat', 'dog', 'cow'])
'cat | dog | cow'
你可能会读到类似于上述示例的代码,尽管数据更具相关性。因此,识别这些构造很重要。然而,这些构造有被认为更符合 Python 风格的替代方案。在“Lambda 的替代方案”一节中,你将学习如何将高阶函数及其伴随的 Lambdas 转换为其他更惯用的形式。
关键字函数(Key Functions)
Python 中的关键字函数是接受名为 key 的参数的高阶函数。key 接收一个函数,该函数可以是 Lambda。此函数直接影响由关键字函数本身驱动的算法。以下是一些关键字函数:
sort():列表方法sorted()、min()、max():内置函数nlargest()和nsmallest():堆队列算法模块heapq中的函数
假设你想对表示为字符串的 ID 列表进行排序。每个 ID 都是字符串 id 和一个数字的拼接。使用内置函数 sorted() 对此列表进行排序时,默认使用字典序,因为列表中的元素是字符串。
为了影响排序执行,你可以将 Lambda 分配给命名参数 key,以便排序使用与 ID 关联的数字:
>>> ids = ['id1', 'id2', 'id30', 'id3', 'id22', 'id100']
>>> print(sorted(ids)) # 字典序排序
['id1', 'id100', 'id2', 'id22', 'id3', 'id30']
>>> sorted_ids = sorted(ids, key=lambda x: int(x[2:])) # 整数排序
>>> print(sorted_ids)
['id1', 'id2', 'id3', 'id22', 'id30', 'id100']
UI 框架
像 Tkinter、wxPython 或 .NET Windows Forms(配合 IronPython)这样的 UI 框架利用 Lambda 函数来映射响应 UI 事件的操作。
下面的简单 Tkinter 程序演示了将 Lambda 分配给 Reverse 按钮的 command:
import tkinter as tk
import sys
window = tk.Tk()
window.grid_columnconfigure(0, weight=1)
window.title("Lambda")
window.geometry("300x100")
label = tk.Label(window, text="Lambda Calculus")
label.grid(column=0, row=0)
button = tk.Button(
window,
text="Reverse",
command=lambda: label.configure(text=label.cget("text")[::-1]),
)
button.grid(column=0, row=1)
window.mainloop()
点击 Reverse 按钮会触发一个事件,该事件触发 Lambda 函数,将标签从 Lambda Calculus 更改为 suluclaC adbmaL。
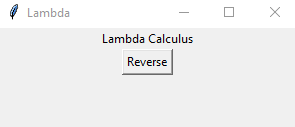
wxPython 和 .NET 平台上的 IronPython 采用类似的方法处理事件。请注意,Lambda 是处理触发事件的一种方式,但也可以使用函数实现相同目的。当所需代码量非常少时,使用 Lambda 更加自包含且简洁。
Python 解释器
当你在交互式解释器中试验 Python 代码时,Python Lambda 函数常常是一种福音。很容易编写一个快速的单行函数来探索一些代码片段,这些片段在解释器之外永远不会被使用。为了快速发现而在解释器中编写的 Lambdas 就像草稿纸,用完就可以扔掉。
timeit
与在 Python 解释器中进行实验的精神相同,timeit 模块提供了对小段代码进行计时的函数。特别是 timeit.timeit() 可以直接调用,并传入一个字符串形式的 Python 代码。示例如下:
>>> from timeit import timeit
>>> timeit("factorial(999)", "from math import factorial", number=10)
0.0013087529951008037
当语句以字符串形式传递时,timeit() 需要完整的上下文。在上面的示例中,这是由第二个参数提供的,该参数设置了主函数计时所需的环境。如果不这样做,会引发 NameError 异常。
另一种方法是使用 Lambda:
>>> from math import factorial
>>> timeit(lambda: factorial(999), number=10)
0.0012704220062005334
这种解决方案更干净、更易读,并且在解释器中输入更快。尽管 Lambda 版本的执行时间略短,但再次执行函数可能会显示字符串版本略有优势。设置的执行时间不包括在总体执行时间中,不应影响结果。
Monkey Patching(猴子补丁)
在测试时,有时需要依赖可重复的结果,即使在给定软件的正常执行过程中,相应结果预期会有所不同,甚至是完全随机的。
假设你想测试一个在运行时处理随机值的函数。但在测试执行期间,你需要以可重复的方式对可预测的值进行断言。以下示例展示了如何通过 Lambda 函数,利用 monkey patching 来帮助你:
from contextlib import contextmanager
import secrets
def gen_token():
"""Generate a random token."""
return f'TOKEN_{secrets.token_hex(8)}'
@contextmanager
def mock_token():
"""Context manager to monkey patch the secrets.token_hex
function during testing.
"""
default_token_hex = secrets.token_hex
secrets.token_hex = lambda _: 'feedfacecafebeef'
yield
secrets.token_hex = default_token_hex
def test_gen_token():
"""Test the random token."""
with mock_token():
assert gen_token() == f"TOKEN_{'feedfacecafebeef'}"
test_gen_token()
上下文管理器有助于隔离 monkey patching 标准库函数(在此示例中为 secrets)的操作。分配给 secrets.token_hex() 的 Lambda 函数通过返回静态值来替代默认行为。
这允许以可预测的方式测试任何依赖 token_hex() 的函数。在退出上下文管理器之前,token_hex() 的默认行为被重新建立,以消除可能影响测试其他区域的意外副作用(这些区域可能依赖 token_hex() 的默认行为)。
像 unittest 和 pytest 这样的单元测试框架将这一概念提升到了更高的复杂程度。
使用 pytest,同样的示例变得更加优雅和简洁:
import secrets
def gen_token():
return f'TOKEN_{secrets.token_hex(8)}'
def test_gen_token(monkeypatch):
monkeypatch.setattr('secrets.token_hex', lambda _: 'feedfacecafebeef')
assert gen_token() == f"TOKEN_{'feedfacecafebeef'}"
通过 pytest 的 monkeypatch fixture,secrets.token_hex() 被覆盖为一个返回确定值 feedfacecafebeef 的 Lambda,从而允许验证测试。pytest 的 monkeypatch fixture 允许你控制覆盖的范围。在上面的示例中,在后续测试中调用 secrets.token_hex()(不使用 monkey patching)将执行此函数的正常实现。
执行 pytest 测试会得到以下结果:
$ pytest test_token.py -v
============================= test session starts ==============================
platform linux -- Python 3.7.2, pytest-4.3.0, py-1.8.0, pluggy-0.9.0
cachedir: .pytest_cache
rootdir: /home/andre/AB/tools/bpython, inifile:
collected 1 item
test_token.py::test_gen_token PASSED [100%]
=========================== 1 passed in 0.01 seconds ===========================
测试通过,因为我们验证了 gen_token() 被执行,并且在测试上下文中结果符合预期。
Lambda 的替代方案
虽然使用 Lambda 有充分的理由,但在某些情况下它的使用是不被鼓励的。那么有哪些替代方案呢?
高阶函数如 map()、filter() 和 functools.reduce() 可以通过稍加创意转换为更优雅的形式,特别是使用列表推导式或生成器表达式。
Map
内置函数 map() 以函数作为第一个参数,并将其应用于第二个参数(一个可迭代对象)的每个元素。可迭代对象的例子包括字符串、列表和元组。
map() 返回一个对应于转换后集合的迭代器。例如,如果你想将字符串列表转换为每个字符串首字母大写的新列表,可以使用 map(),如下所示:
>>> list(map(lambda x: x.capitalize(), ['cat', 'dog', 'cow']))
['Cat', 'Dog', 'Cow']
你需要调用 list() 将 map() 返回的迭代器转换为可在 Python shell 解释器中显示的扩展列表。
使用列表推导式可以消除定义和调用 Lambda 函数的需要:
>>> [x.capitalize() for x in ['cat', 'dog', 'cow']]
['Cat', 'Dog', 'Cow']
Filter
内置函数 filter() 是另一个经典的函数式构造,可以转换为列表推导式。它以谓词作为第一个参数,以可迭代对象作为第二个参数。它构建一个迭代器,包含初始集合中满足谓词函数的所有元素。以下示例过滤给定整数列表中的所有偶数:
>>> even = lambda x: x%2 == 0
>>> list(filter(even, range(11)))
[0, 2, 4, 6, 8, 10]
注意,filter() 返回一个迭代器,因此需要调用内置类型 list 来根据迭代器构造列表。
使用列表推导式构造的实现如下:
>>> [x for x in range(11) if x%2 == 0]
[0, 2, 4, 6, 8, 10]
Reduce
从 Python 3 开始,reduce() 从内置函数变为 functools 模块中的函数。与 map() 和 filter() 一样,它的前两个参数分别是函数和可迭代对象。它还可以接受第三个参数作为初始值,用于初始化结果累加器。对于可迭代对象的每个元素,reduce() 应用函数并累加结果,在可迭代对象耗尽时返回该结果。
要对一对列表应用 reduce() 并计算每对中第一个项目的总和,你可以这样写:
>>> import functools
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> functools.reduce(lambda acc, pair: acc + pair[0], pairs, 0)
6
使用生成器表达式作为 sum() 的参数,这是一种更符合 Python 风格的方法:
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> sum(x[0] for x in pairs)
6
一个稍有不同的、可能更清晰的解决方案通过解包消除了显式访问对的第一个元素的需要:
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> sum(x for x, _ in pairs)
6
下划线 _ 的使用是 Python 的一种约定,表示你可以忽略对的第二个值。
sum() 接受唯一参数,因此生成器表达式不需要括号。
Lambda 是否符合 Python 风格?
PEP 8(Python 代码风格指南)写道:
始终使用
def语句,而不是将 Lambda 表达式直接绑定到标识符的赋值语句。
这强烈不鼓励将 Lambda 绑定到标识符,主要是因为在应该使用函数的地方,函数能带来更多好处。PEP 8 没有提及 Lambda 的其他用法。正如你在前几节中看到的,Lambda 函数当然有很好的用途,尽管它们是有限的。
回答这个问题的一种可能方式是:如果没有任何更符合 Python 风格的替代方案,那么 Lambda 函数就是符合 Python 风格的。我避免定义“Pythonic”的含义,留给你最适合你思维模式以及你个人或团队编码风格的定义。
结论
你现在知道如何使用 Python Lambda 函数,并且可以:
- 编写 Python Lambdas 并使用匿名函数
- 在 Lambdas 和普通 Python 函数之间明智地选择
- 避免过度使用 Lambdas
- 将 Lambdas 与高阶函数或 Python 关键字函数结合使用
如果你对数学有浓厚兴趣,你可能会在探索迷人的 Lambda 演算世界中获得乐趣。
Python Lambdas 就像盐。在你的火腿蛋中加一小撮会提升风味,但太多就会毁掉整道菜。