Jakob Jenkov 2015-06-26
阿姆达尔定律可用于计算通过并行执行程序的一部分所能获得的加速比。该定律由 Gene Amdahl 于 1967 年提出。大多数从事并行或并发系统开发的程序员即使不了解阿姆达尔定律,也对潜在的加速效果有直观感受。尽管如此,了解阿姆达尔定律仍然很有用。
我将首先从数学角度解释阿姆达尔定律,然后通过图示进一步说明。
阿姆达尔定律的定义
一个可以并行化的程序(或算法)可被划分为两个部分:
- 无法并行化的部分
- 可以并行化的部分
设想一个从磁盘读取文件进行处理的程序。该程序的一小部分可能会扫描目录并在内存中创建一个文件列表。之后,每个文件会被传递给一个独立的线程进行处理。其中,扫描目录并创建文件列表的部分无法并行化,而处理各个文件的部分可以并行化。
程序在串行(非并行)方式下执行所需的总时间记为 T。这个时间 T 包含了不可并行部分和可并行部分的时间。不可并行部分的时间记为 B,可并行部分的时间则为 T - B。以下是这些定义的总结:
- T = 串行执行的总时间
- B = 不可并行部分的总时间
- T - B = 可并行部分的总时间(以串行方式执行时)
由此可得:
T = B + (T - B)
初看之下,可并行部分在公式中没有单独的符号似乎有些奇怪。但实际上,由于可并行部分可以用总时间 T 和不可并行部分 B 表示,因此这个公式在概念上已经被简化了——变量数量减少了。
真正能通过并行执行来加速的是可并行部分 T - B。其加速程度取决于你使用了多少个线程或 CPU 核心,这个数量记为 N。因此,可并行部分最快可在 (T - B) / N 的时间内完成。
也可以写成:
(1 / N) * (T - B)
维基百科采用的就是这种形式。
根据阿姆达尔定律,当可并行部分使用 N 个线程或 CPU 执行时,程序的总执行时间为:
T(N) = B + (T - B) / N
其中,T(N) 表示并行因子为 N 时的总执行时间。因此,原来的 T 也可以写作 T(1),即并行因子为 1(完全串行)时的执行时间。于是阿姆达尔定律也可表示为:
T(N) = B + (T(1) - B) / N
两种写法含义相同。
计算示例
为了更好地理解阿姆达尔定律,我们来看一个计算示例。
假设程序的总执行时间为 1(归一化处理)。其中,不可并行部分占 40%,即 B = 0.4,那么可并行部分就是 1 - 0.4 = 0.6。
当并行因子 N = 2(即使用 2 个线程或 CPU)时,程序的执行时间为:
T(2) = 0.4 + (1 - 0.4) / 2
= 0.4 + 0.6 / 2
= 0.4 + 0.3
= 0.7
若并行因子 N = 5,则:
T(5) = 0.4 + (1 - 0.4) / 5
= 0.4 + 0.6 / 5
= 0.4 + 0.12
= 0.52
阿姆达尔定律图解
为了更直观地理解阿姆达尔定律,下面通过图示说明其推导过程。
首先,一个程序可分为不可并行部分 B 和可并行部分 1 - B,如下图所示:
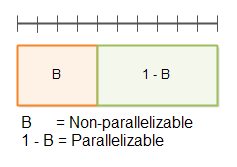
顶部带分隔符的线表示总时间 T(1)。
当并行因子为 2 时的执行时间如下图:
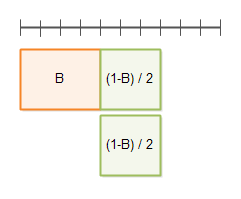
当并行因子为 3 时:
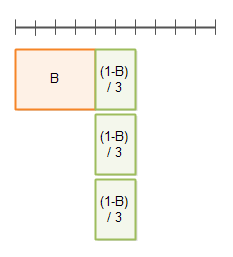
算法优化
从阿姆达尔定律可以自然得出:可并行部分可以通过增加硬件资源(更多线程/CPU)来加速;而不可并行部分只能通过代码优化来提速。
因此,你可以通过优化不可并行部分来提升整体性能。甚至可以考虑改进算法,将部分工作从不可并行部分转移到可并行部分(如果可行的话),从而减少 B 的占比。
优化串行部分
如果你对程序的串行(不可并行)部分进行了优化,也可以用阿姆达尔定律计算优化后的执行时间。
假设不可并行部分 B 被优化了 O 倍(即原来耗时 B,现在只需 B/O),那么阿姆达尔定律变为:
T(O, N) = B / O + (1 - B / O) / N
这里,不可并行部分耗时 B / O,可并行部分耗时 1 - B / O。
例如,若 B = 0.4,O = 2(串行部分提速 2 倍),N = 5(并行因子为 5),则:
T(2, 5) = 0.4 / 2 + (1 - 0.4 / 2) / 5
= 0.2 + (1 - 0.2) / 5
= 0.2 + 0.8 / 5
= 0.2 + 0.16
= 0.36
执行时间 vs. 加速比
到目前为止,我们只用阿姆达尔定律计算了优化或并行化后的执行时间。其实它也可以用来计算加速比(speedup),即新版本比旧版本快多少倍。
如果旧版本的执行时间为 T,则加速比为:
Speedup = T / T(O, N)
通常我们将 T 设为 1(归一化),于是:
Speedup = 1 / T(O, N)
代入阿姆达尔公式:
Speedup = 1 / (B / O + (1 - B / O) / N)
仍以 B = 0.4,O = 2,N = 5 为例:
Speedup = 1 / (0.4/2 + (1 - 0.4/2)/5)
= 1 / (0.2 + 0.8/5)
= 1 / (0.2 + 0.16)
= 1 / 0.36
≈ 2.78
这意味着:串行部分提速 2 倍,并行部分使用 5 个线程,整体最多可提速约 2.78 倍。
实测胜于理论计算
虽然阿姆达尔定律能帮助你理论估算并行化带来的加速效果,但不要过度依赖这些计算。在实际优化中,许多其他因素会影响最终性能:
- 内存带宽
- CPU 缓存命中率
- 磁盘或网络 I/O(如果涉及)
- 总线饱和、锁竞争、上下文切换开销等
例如,即使你用了 N 个 CPU,但如果并行版本导致大量缓存未命中(cache miss),实际加速可能远低于理论值。同样,如果内存总线、磁盘或网络成为瓶颈,并行化也无法带来预期收益。
建议:用阿姆达尔定律指导优化方向,但务必通过实际测量来验证真实加速效果。有时,高度串行的单线程算法反而比并行版本更快——因为它没有任务拆分与合并的协调开销,且更符合底层硬件特性(如 CPU 流水线、缓存局部性等)。