Jakob Jenkov 2021-07-26
Java 中的伪共享(False Sharing)发生在两个运行在不同 CPU 上的线程,分别写入两个不同的变量,而这两个变量恰好位于同一个 CPU 缓存行(Cache Line)中。当第一个线程修改其中一个变量时,整个缓存行会在另一个 CPU 的缓存中被标记为无效(即使另一个线程并不需要这个被修改的变量)。这意味着其他 CPU 必须重新加载该缓存行的内容,从而导致性能损失。
伪共享示意图
下图展示了 Java 中伪共享的情形:
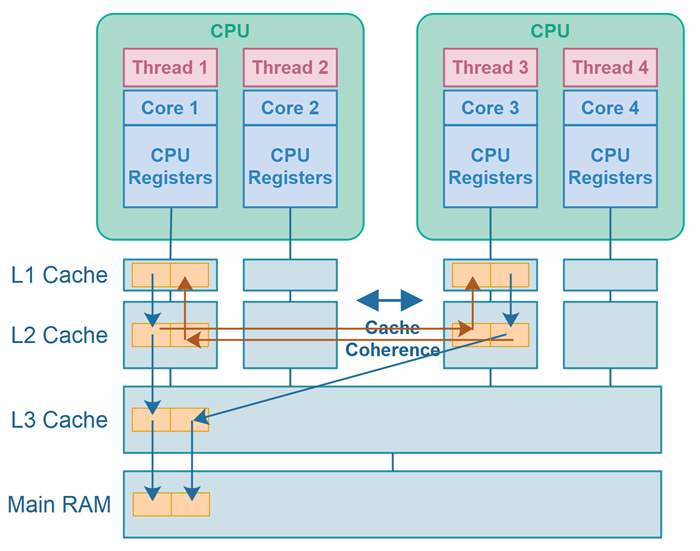
图中显示了两个运行在不同 CPU 上的线程,它们分别写入不同的变量,但这些变量恰好存储在同一个 CPU 缓存行中,从而引发伪共享。
缓存行(Cache Lines)
CPU 缓存在从低层级缓存或主内存(例如 L1 从 L2、L2 从 L3、L3 从主内存)读取数据时,并不会一次只读一个字节,因为那样效率太低。相反,它会一次性读取一个缓存行(Cache Line)。一个典型的缓存行大小为 64 字节。
由于缓存行包含多个字节,因此单个缓存行通常会存储多个变量。如果同一个 CPU 需要访问同一缓存行中的多个变量,这是有利的;但如果多个 CPU 需要访问同一缓存行中的不同变量,就可能发生伪共享。
缓存行失效(Cache Line Invalidation)
当某个 CPU 向缓存行中的某个内存地址写入数据(通常是写入某个变量)时,该缓存行会被标记为“脏”(dirty)。此时,其他也缓存了该缓存行的 CPU 必须同步这一变化,即它们缓存中的相同缓存行将被标记为无效,必须重新加载。
在上图中,缓存行变“脏”用蓝色线表示,缓存行失效用红色箭头表示。
缓存刷新可以通过缓存一致性协议(cache coherence mechanisms)完成,也可以直接从主内存重新加载。
在缓存行刷新完成之前,CPU 不允许访问该缓存行。
伪共享会导致性能惩罚
当一个缓存行因其他 CPU 修改其中的数据而失效时,该 CPU 必须等待缓存行刷新完成后才能继续使用。这会浪费 CPU 时间,降低整体执行效率。
伪共享的本质是:两个(或更多)CPU 分别写入同一缓存行中的不同变量,彼此并不依赖对方写入的值,但由于共用缓存行,导致频繁地使对方的缓存行失效,进而不断触发缓存刷新,形成恶性循环。
解决伪共享的方法是:调整数据结构,确保被不同线程独立使用的变量不落在同一个缓存行中。
注意:即使 CPU 偶尔会使用对方写入的变量,将共享变量分离到不同缓存行仍可能带来性能提升。具体效果需根据实际情况进行测试。
Java 伪共享代码示例
以下两个类展示了 Java 应用中可能出现伪共享的情况。
第一个类是一个 Counter 类,会被两个线程使用。第一个线程递增 count1 字段,第二个线程递增 count2 字段。
public class Counter {
public volatile long count1 = 0;
public volatile long count2 = 0;
}
下面是启动两个线程、分别对同一个 Counter 实例的两个字段进行递增的示例代码:
public class FalseSharingExample {
public static void main(String[] args) {
Counter counter1 = new Counter();
Counter counter2 = counter1; // 注意:这里两个线程共享同一个实例!
long iterations = 1_000_000_000;
Thread thread1 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for (long i = 0; i < iterations; i++) {
counter1.count1++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
Thread thread2 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for (long i = 0; i < iterations; i++) {
counter2.count2++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
thread1.start();
thread2.start();
}
}
在我的笔记本电脑上,运行上述代码大约需要 36 秒。
但如果将代码稍作修改,让每个线程使用各自独立的 Counter 实例(如下所示),运行时间则降至约 9 秒 —— 性能提升了 4 倍!
造成这种巨大差异的原因极有可能是:在第一个例子中,count1 和 count2 字段在运行时位于同一个缓存行中,引发了伪共享;而在第二个例子中,两个线程操作的是不同对象,字段不再共享缓存行,因此避免了伪共享。
修改后的代码(仅一行不同,已加粗):
public class FalseSharingExample {
public static void main(String[] args) {
Counter counter1 = new Counter();
Counter counter2 = new Counter(); // ← 关键修改:创建两个独立实例
long iterations = 1_000_000_000;
Thread thread1 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for (long i = 0; i < iterations; i++) {
counter1.count1++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
Thread thread2 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for (long i = 0; i < iterations; i++) {
counter2.count2++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
thread1.start();
thread2.start();
}
}
如何修复伪共享问题
解决伪共享的核心思路是:确保被不同线程使用的独立变量不存储在同一个 CPU 缓存行中。
具体方法取决于你的代码结构。一种简单方式就是像上面示例那样,将变量分配到不同的对象实例中。
使用 @Contended 注解防止伪共享
从 Java 8 和 Java 9 开始,JVM 提供了 @Contended 注解,可以在类的字段之间插入填充字节(padding),从而确保这些字段不会落在同一个缓存行中。
下面是在前面示例的 Counter 类中为 count1 字段添加 @Contended 注解的版本。添加后,执行时间降至与使用两个独立实例相当的水平(约 9 秒):
public class Counter1 {
@jdk.internal.vm.annotation.Contended
public volatile long count1 = 0;
public volatile long count2 = 0;
}
⚠️ 注意:
@Contended是jdk.internal包下的内部 API,默认情况下可能无法直接使用。你可能需要添加 JVM 参数--add-exports java.base/jdk.internal.vm.annotation=ALL-UNNAMED才能编译通过。
对类使用 @Contended
你也可以将 @Contended 注解放在类上,这样类中的所有字段都会相互隔离(每个字段前后都加 padding):
@jdk.internal.vm.annotation.Contended
public class Counter1 {
public volatile long count1 = 0;
public volatile long count2 = 0;
}
但在我的测试中,这种方式并未显著提升性能,而只注解第一个字段却有效。因此,务必对不同方案进行性能测量后再做选择。
对字段使用 @Contended
你也可以只为特定字段添加注解,以隔离它们:
public class Counter1 {
@jdk.internal.vm.annotation.Contended
public volatile long count1 = 0;
@jdk.internal.vm.annotation.Contended
public volatile long count2 = 0;
}
字段分组(Grouping Fields)
@Contended 还支持分组功能:同一组内的字段会紧凑存放,但与其他组之间会有填充。
public class Counter1 {
@jdk.internal.vm.annotation.Contended("group1")
public volatile long count1 = 0;
@jdk.internal.vm.annotation.Contended("group1")
public volatile long count2 = 0;
@jdk.internal.vm.annotation.Contended("group2")
public volatile long count3 = 0;
}
在这个例子中:
count1和count2属于group1,它们会紧挨着存放;count3属于group2,它与group1之间会有填充。
组名本身没有特殊含义,仅用于标识哪些字段属于同一组。
配置填充大小
默认情况下,@Contended 会在注解字段后添加 128 字节的填充。你可以通过 JVM 参数自定义填充大小:
-XX:ContendedPaddingWidth=64
这会将填充大小设为 64 字节。
提示:填充大小应根据底层硬件的缓存行大小来设置。如果 CPU 缓存行是 64 字节,那么 128 字节填充就有些浪费;如果是 256 字节,则 128 字节填充可能不足以避免伪共享。