Jakob Jenkov 2015-03-30
在并发编程的上下文中,无锁算法(Non-blocking Algorithms)是指允许多个线程访问共享状态(或以其他方式协作、通信)而不会阻塞参与线程的算法。更一般地说,如果一个算法中某个线程的挂起(暂停)不会导致其他参与该算法的线程也被挂起,那么这个算法就被称为无锁算法。
为了更好地理解阻塞与无锁并发算法之间的区别,我将先解释阻塞算法,然后再介绍无锁算法。
阻塞并发算法(Blocking Concurrency Algorithms)
阻塞并发算法是指满足以下条件之一的算法:
- A:执行线程所请求的操作;或者
- B:阻塞该线程,直到可以安全地执行该操作为止。
许多类型的算法和并发数据结构都是阻塞的。例如,java.util.concurrent.BlockingQueue 接口的不同实现都是阻塞数据结构。如果一个线程试图向一个已满的 BlockingQueue 插入元素,该插入线程会被阻塞(挂起),直到队列中有空间容纳新元素。
下图展示了保护共享数据结构的阻塞算法的行为:
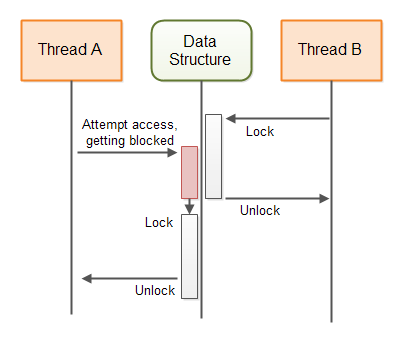
无锁并发算法(Non-blocking Concurrency Algorithms)
无锁并发算法是指满足以下条件之一的算法:
- A:执行线程所请求的操作;或者
- B:通知请求线程该操作无法执行。
Java 中也包含若干无锁数据结构。例如:
这些都是无锁数据结构的例子。
下图展示了保护共享数据结构的无锁算法的行为:
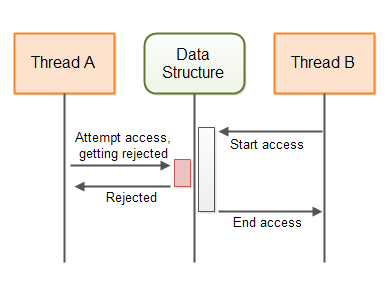
无锁 vs 阻塞算法
阻塞与无锁算法的主要区别在于当所请求的操作无法立即执行时,它们的处理方式不同:
- 阻塞算法会挂起线程,直到操作可以安全执行;
- 无锁算法则会立即通知线程“操作无法执行”。
使用阻塞算法时,线程可能会被无限期挂起,直到其他线程完成某些操作使其请求变得可行。通常,正是其他线程的行为使得第一个线程能够继续执行。但如果那个“其他线程”由于某种原因在应用程序的其他地方被挂起(阻塞),那么第一个线程也将一直被阻塞——可能是无限期地,或者直到那个线程最终执行了必要的操作。
举例:
如果一个线程试图向一个已满的 BlockingQueue 插入元素,它将被阻塞,直到另一个线程从队列中取出一个元素。如果负责取元素的线程因故在别处被阻塞,那么插入线程就会一直等待。
相比之下,无锁算法不会造成这种连锁阻塞。
无锁并发数据结构(Non-blocking Concurrent Data Structures)
在多线程系统中,线程通常通过某种数据结构进行通信。这些数据结构可以是简单的变量,也可以是更复杂的结构,如队列、映射(Map)、栈等。为了确保多个线程能正确并发地访问这些数据结构,必须由某种并发算法来保护它们。这种保护算法决定了该数据结构是否为“并发数据结构”。
- 如果保护算法是阻塞的(使用线程挂起),则称为阻塞并发数据结构;
- 如果保护算法是无锁的,则称为无锁并发数据结构。
每种并发数据结构都设计用于支持特定的通信模式。因此,选择哪种并发数据结构取决于你的通信需求。接下来几节将介绍一些无锁并发数据结构,并说明它们适用的场景。这些例子也能帮助你理解如何设计和实现无锁数据结构。
volatile 变量(Volatile Variables)
Java 的 volatile 变量总是直接从主内存中读取。当给 volatile 变量赋新值时,该值也会立即写回主内存。这保证了 volatile 变量的最新值对运行在其他 CPU 上的其他线程始终可见——其他线程每次都会从主内存读取,而不是从 CPU 缓存中读取。
volatile 变量是无锁的。对 volatile 变量的单次写入是原子操作,不可中断。
但是,对 volatile 变量执行“读-修改-写”序列不是原子的。因此,以下代码在多线程环境下仍可能导致竞态条件:
volatile int myVar = 0;
...
int temp = myVar;
temp++;
myVar = temp;
两个线程可能同时读取 myVar 的值(比如 19),各自加 1 后都写回 20,导致最终结果只增加了 1 而不是 2。
你可能会想:“我不会写这样的代码”,但实际上下面这行代码在底层就是上述操作:
myVar++;
执行时,myVar 的值被加载到 CPU 寄存器或缓存中,加 1,再写回主内存。
单写者场景(The Single Writer Case)
在某些情况下,只有一个线程写入共享变量,而多个线程读取它。此时不会发生竞态条件,因为竞态只会在多个线程同时执行“读-修改-写”时出现。
因此,只要共享变量只有一个写入者,就可以安全地使用 volatile 变量。
下面是一个单写者计数器的例子,它不使用同步但仍具备线程安全性:
public class SingleWriterCounter {
private volatile long count = 0;
/**
* 只能由同一个线程调用此方法,
* 否则会导致竞态条件。
*/
public void inc() {
this.count++;
}
/**
* 多个读线程可调用此方法
*/
public long count() {
return this.count;
}
}
多个线程可以访问同一个 SingleWriterCounter 实例,但必须确保只有同一个线程调用 inc()(不是“一次一个”,而是“永远是同一个”)。多个线程可以安全地调用 count()。
下图展示了线程如何访问这个 volatile 的 count 变量:
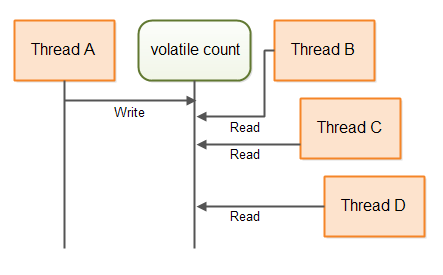
基于 volatile 的更复杂数据结构
可以构建使用多个 volatile 变量组合的数据结构,其中每个 volatile 变量仅由一个线程写入,但可被多个线程读取。不同的 volatile 变量可以由不同的线程写入(但每个变量仍只对应一个写入者)。这种结构允许多个线程以无锁方式相互通信。
下面是一个双写者计数器的简单示例:
public class DoubleWriterCounter {
private volatile long countA = 0;
private volatile long countB = 0;
/**
* 只能由同一个线程调用此方法
*/
public void incA() {
this.countA++;
}
/**
* 只能由同一个线程(可以不同于 incA 的线程)调用此方法
*/
public void incB() {
this.countB++;
}
public long countA() { return this.countA; }
public long countB() { return this.countB; }
}
- 线程 A 调用
incA(),线程 B 调用incB(); - 多个线程可读取
countA()和countB(); - 不会产生竞态条件。
这种结构可用于两个线程之间的通信,例如:countA 表示任务生产数量,countB 表示任务消费数量。
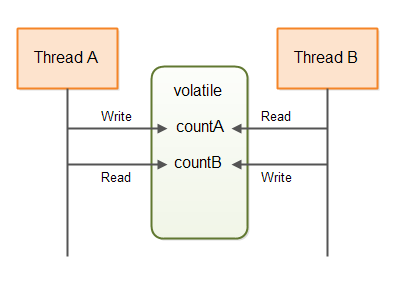
提示:聪明的读者会发现,你完全可以使用两个
SingleWriterCounter实例来达到同样效果,甚至可以扩展到更多线程。
使用 CAS 的乐观锁(Optimistic Locking With Compare and Swap)
如果你确实需要多个线程写入同一个共享变量,那么 volatile 就不够用了,你需要某种形式的互斥访问。传统做法是使用 synchronized 块:
public class SynchronizedCounter {
long count = 0;
public void inc() {
synchronized(this) {
count++;
}
}
public long count() {
synchronized(this) {
return this.count;
}
}
}
但我们希望避免 synchronized 块以及 wait()/notify() 等阻塞操作。
替代方案是使用 Java 的原子变量,例如 AtomicLong:
import java.util.concurrent.atomic.AtomicLong;
public class AtomicCounter {
private AtomicLong count = new AtomicLong(0);
public void inc() {
boolean updated = false;
while (!updated) {
long prevCount = this.count.get();
updated = this.count.compareAndSet(prevCount, prevCount + 1);
}
}
public long count() {
return this.count.get();
}
}
这个版本和 synchronized 版本一样线程安全,但 inc() 方法中没有同步块。
关键在于 compareAndSet()(CAS)方法:
- 它是原子操作,由 CPU 的 compare-and-swap 指令直接支持;
- 它比较当前值是否等于预期值,如果是,则更新为新值;
- 无需线程挂起,无锁开销。
执行过程:
- 两个线程同时读取
count = 20; - 两者都尝试
compareAndSet(20, 21); - 第一个线程成功,
count变为 21; - 第二个线程失败(因为当前值已是 21 ≠ 20),于是重试:读取 21,尝试
compareAndSet(21, 22); - 若无其他干扰,第二次尝试成功。
为什么叫“乐观锁”?(Why is it Called Optimistic Locking?)
上述机制称为乐观锁(Optimistic Locking),与传统的悲观锁(Pessimistic Locking,如 synchronized)相对。
- 悲观锁:假设冲突一定会发生,因此提前加锁,阻止其他线程访问;
- 乐观锁:假设冲突不太可能发生,因此允许所有线程自由读取并修改本地副本,只在提交时检查是否冲突。
如果提交时发现共享内存已被他人修改,则放弃本次修改,重新读取、修改、再尝试提交。
适用场景:低到中等竞争。高竞争下,大量重试会浪费 CPU 资源,此时应考虑降低竞争或改用其他方案。
乐观锁是非阻塞的(Optimistic Locking is Non-blocking)
乐观锁机制是非阻塞的:
- 如果一个线程在修改其副本时被挂起,不会影响其他线程访问共享内存;
- 而在传统锁机制中,持有锁的线程若被挂起,会导致其他线程无限期等待。
不可整体替换的数据结构(Non-swappable Data Structures)
前述 CAS 方法适用于可以整体替换的数据结构(如整数、引用)。但对于大型结构(如队列),每次都复制整个结构代价高昂:
- 内存消耗大;
- CPU 开销高;
- 修改耗时越长,被他人抢先修改的概率越高,导致更多重试。
因此,我们需要更高效的方法。
共享“意图修改”(Sharing Intended Modifications)
替代方案:不复制整个结构,而是共享“修改意图”。
流程如下:
- 检查是否有其他线程已提交“修改意图”;
- 若无,则创建一个“修改意图对象”并提交(通过 CAS);
- 执行实际修改;
- 移除“修改意图”标记,表示修改完成。
第二步相当于一个轻量级锁:一旦有线程提交了修改意图,其他线程就不能再提交,直到当前修改完成。
但问题来了:如果提交修改意图的线程被挂起怎么办? 整个数据结构就被“锁死”了。
可被他人完成的修改(Completable Intended Modifications)
解决方案:“修改意图对象”必须包含足够信息,让其他线程也能完成该修改。
这样,即使原线程挂起,其他线程也可以“帮忙”完成修改,保持数据结构可用。
下图展示了这种无锁算法的蓝图:
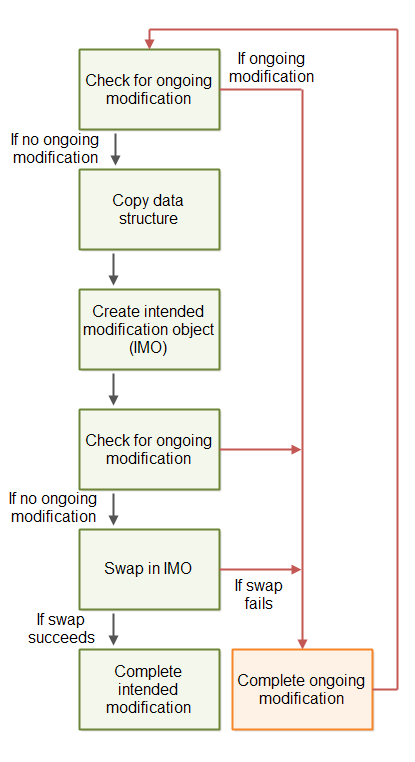
所有实际修改仍需通过 CAS 操作完成,确保原子性。
A-B-A 问题(The A-B-A Problem)
上述算法可能遭遇 A-B-A 问题:
- 线程 A 读取变量值为 A;
- 线程 A 被挂起;
- 线程 B 将变量从 A → B → A;
- 线程 A 恢复,发现值仍是 A,认为未被修改,于是基于过期数据执行操作,覆盖了 B 的修改。
下图说明了该问题:
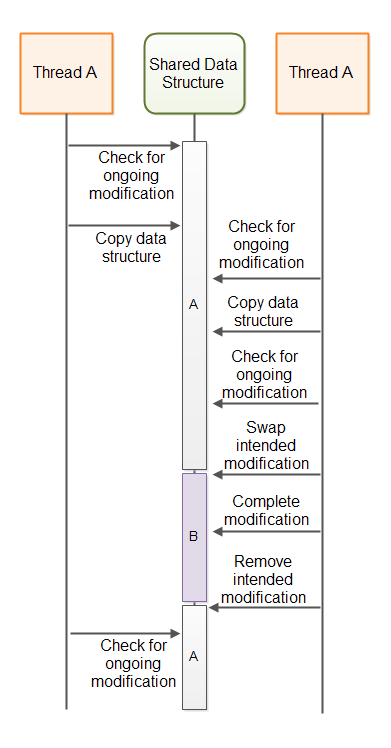
A-B-A 问题的解决方案(A-B-A Solutions)
常见解决方案:将指针与版本号(stamp)打包,一起进行 CAS。
- 在 C/C++ 中,可将指针和计数器合并为一个机器字;
- 在 Java 中,可使用
AtomicStampedReference,它能原子地交换引用和 stamp。
即使引用值恢复为原值,stamp 已改变,从而检测到中间修改。
无锁算法模板(A Non-blocking Algorithm Template)
以下是一个概念性模板(仅供理解,勿直接用于生产):
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.atomic.AtomicStampedReference;
public class NonblockingTemplate {
public static class IntendedModification {
public AtomicBoolean completed = new AtomicBoolean(false);
}
private AtomicStampedReference<IntendedModification> ongoingMod =
new AtomicStampedReference<>(null, 0);
// 数据结构状态声明在此
public void modify() {
while (!attemptModifyASR());
}
public boolean attemptModifyASR() {
IntendedModification currentMod = ongoingMod.getReference();
int stamp = ongoingMod.getStamp();
if (currentMod == null) {
// 准备修改
IntendedModification newMod = new IntendedModification();
boolean submitted = ongoingMod.compareAndSet(null, newMod, stamp, stamp + 1);
if (submitted) {
// 执行修改(通过一系列 CAS)
// 其他线程也可协助完成
return true;
}
} else {
// 尝试完成他人未完成的修改
// ...
}
return false;
}
}
⚠️ 注意:无锁算法极难正确实现。建议优先使用 JDK 或成熟开源库(如 LMAX Disruptor、Cliff Click 的非阻塞 HashMap)提供的实现。
无锁算法的优势(The Benefit of Non-blocking Algorithms)
1. 选择权(Choice)
线程在操作无法执行时有选择权:可以重试、做其他事、或自行挂起。而不是被动阻塞。
2. 无死锁(No Deadlocks)
由于线程不会因等待资源而被挂起,因此不可能发生死锁(但仍可能发生活锁)。
3. 无线程挂起开销(No Thread Suspension)
线程挂起/唤醒涉及操作系统上下文切换,开销大。无锁算法避免了这一开销,CPU 更多地用于业务逻辑。
4. 降低线程延迟(Reduced Thread Latency)
线程响应更快:一旦操作可行,无需等待调度器唤醒,可立即执行。
注意:无锁算法常使用“忙等待”(busy-wait),在高竞争场景下可能浪费 CPU。应根据实际情况权衡。
总结
无锁算法通过避免线程阻塞,提升了并发性能和系统响应性。但其实现复杂,易出错。除非必要,优先使用 JDK 提供的无锁数据结构(如 ConcurrentLinkedQueue)或知名开源库。