Pedro Pregueiro
理解链表
链表是一种有序的对象集合。那么,它与普通列表(list)有什么不同呢?
区别在于它们在内存中存储元素的方式:
- 列表使用一块连续的内存区域来存储对其数据的引用;
- 链表则将引用作为其自身元素的一部分进行存储。
核心概念
在深入探讨链表及其用法之前,首先需要了解它的结构。
链表中的每个元素称为一个 节点(node),每个节点包含两个字段:
- Data(数据):存储节点的值。
- Next(下一个):指向链表中下一个节点的引用。
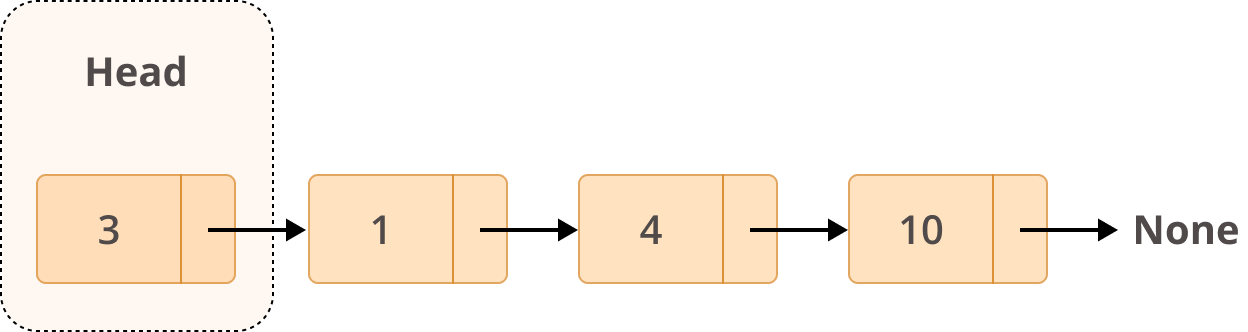
示例:链表中的一个典型节点

链表就是由多个这样的节点组成的集合:
- 第一个节点称为 头节点(head),是遍历链表的起点。
- 最后一个节点的
next必须指向None,以表示链表的结束。
示例:链表的结构
了解了链表的基本结构后,就可以看看它的实际应用场景了。
实际应用
链表在现实世界中有多种用途,例如实现队列、栈或图,甚至可用于操作系统中应用程序的生命周期管理等更复杂的任务。
队列与栈
队列和栈的区别仅在于元素的取出方式:
队列(Queue) 采用 先进先出(FIFO) 策略:
最早插入的元素最先被取出。
栈(Stack) 采用 后进先出(LIFO) 策略:
最后插入的元素最先被取出。
由于队列和栈的操作集中在列表的两端,链表是实现这两种数据结构非常方便的选择。
图(Graphs)
图可用于表示对象之间的关系或各类网络结构。例如,一个有向无环图(DAG) 可能如下所示:
图的一种常见实现方式是 邻接表(Adjacency List) —— 本质上是一个链表的列表,每个顶点都关联一个存储其相邻顶点的链表:
| 顶点 | 相邻顶点链表 |
|---|---|
| 1 | 2 → 3 → None |
| 2 | 4 → None |
| 3 | None |
| 4 | 5 → 6 → None |
| 5 | 6 → None |
| 6 | None |
在代码中,邻接表通常用字典表示(虽然底层常用链表实现):
graph = {
1: [2, 3, None],
2: [4, None],
3: [None],
4: [5, 6, None],
5: [6, None],
6: [None]
}
💡 注:上例中保留了
None仅为清晰展示;实际可省略。
相比邻接矩阵,邻接表在速度和内存上都更高效,因此链表在图的实现中非常有用。
性能对比:列表 vs 链表
在大多数编程语言中,链表和数组在内存中的存储方式差异明显。但在 Python 中,列表实际上是动态数组,因此两者在内存使用上差别不大。
因此,我们更应关注它们在时间复杂度上的性能差异。
插入与删除元素
Python 列表提供了以下方法:
.append()/.pop():在末尾添加/删除(O(1)).insert()/.remove():在任意位置插入/删除(平均 O(n),因为需要移动元素)
而链表在头部或尾部插入/删除的时间复杂度始终为 O(1)。
因此:
- 实现 队列(FIFO) 时,链表性能优于列表(因需频繁操作头部);
- 实现 栈(LIFO) 时,两者性能相近(均操作尾部)。
元素检索
- 按索引访问:列表为 O(1),链表需遍历,为 O(n)
- 按值查找:两者均为 O(n),都需要遍历整个结构
引入 collections.deque
Python 的 collections 模块提供了一个名为 deque(发音“deck”,即 double-ended queue,双端队列)的对象,内部基于链表实现,支持在两端以 O(1) 时间复杂度插入或删除元素。
如何使用 deque
创建空链表:
from collections import deque
deque() # deque([])
用可迭代对象初始化:
deque(['a','b','c']) # deque(['a', 'b', 'c'])
deque('abc') # deque(['a', 'b', 'c'])
deque([{'data': 'a'}, {'data': 'b'}]) # deque([{'data': 'a'}, {'data': 'b'}])
添加/删除元素:
llist = deque("abcde")
llist.append("f") # 末尾添加
llist.pop() # 末尾移除 → 'f'
llist.appendleft("z") # 头部添加
llist.popleft() # 头部移除 → 'z'
如何实现队列和栈
队列(FIFO)
from collections import deque
queue = deque()
queue.append("Mary")
queue.append("John")
queue.append("Susan")
queue.popleft() # 'Mary'
queue.popleft() # 'John'
每次调用 popleft() 都会从链表头部移除元素,完美模拟真实队列。
栈(LIFO)
history = deque()
history.appendleft("https://mianshima.com/")
history.appendleft("https://mianshima.com/pandas-read-write-files/")
history.appendleft("https://mianshima.com/python-csv/")
history.popleft() # 'https://mianshima.com/python-csv/'
history.popleft() # 'https://mianshima.com/pandas-read-write-files/'
通过 appendleft() 和 popleft(),即可实现浏览器历史记录的“后退”功能。
自己实现链表
虽然 deque 很强大,但自己实现链表有助于:
- 练习算法技能
- 理解数据结构原理
- 准备技术面试
创建链表类
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return self.data
class LinkedList:
def __init__(self, nodes=None):
self.head = None
if nodes is not None:
node = Node(data=nodes.pop(0))
self.head = node
for elem in nodes:
node.next = Node(data=elem)
node = node.next
def __repr__(self):
node = self.head
nodes = []
while node is not None:
nodes.append(node.data)
node = node.next
nodes.append("None")
return " -> ".join(nodes)
使用示例:
llist = LinkedList(["a", "b", "c"])
print(llist) # a -> b -> c -> None
遍历链表
通过实现 __iter__ 方法,使链表可迭代:
def __iter__(self):
node = self.head
while node is not None:
yield node
node = node.next
使用:
for node in llist:
print(node.data)
插入新节点
在开头插入
def add_first(self, node):
node.next = self.head
self.head = node
在末尾插入
def add_last(self, node):
if self.head is None:
self.head = node
return
for current_node in self:
pass
current_node.next = node
在指定节点后插入
def add_after(self, target_node_data, new_node):
if self.head is None:
raise Exception("List is empty")
for node in self:
if node.data == target_node_data:
new_node.next = node.next
node.next = new_node
return
raise Exception(f"Node with data '{target_node_data}' not found")
在指定节点前插入
def add_before(self, target_node_data, new_node):
if self.head is None:
raise Exception("List is empty")
if self.head.data == target_node_data:
return self.add_first(new_node)
prev_node = self.head
for node in self:
if node.data == target_node_data:
prev_node.next = new_node
new_node.next = node
return
prev_node = node
raise Exception(f"Node with data '{target_node_data}' not found")
删除节点
def remove_node(self, target_node_data):
if self.head is None:
raise Exception("List is empty")
if self.head.data == target_node_data:
self.head = self.head.next
return
previous_node = self.head
for node in self:
if node.data == target_node_data:
previous_node.next = node.next
return
previous_node = node
raise Exception(f"Node with data '{target_node_data}' not found")
高级链表类型
双向链表(Doubly Linked List)
每个节点包含两个引用:
next:指向下一个节点previous:指向前一个节点
class Node:
def __init__(self, data):
self.data = data
self.next = None
self.previous = None
collections.deque 内部就使用了双向链表,从而支持两端 O(1) 操作。
循环链表(Circular Linked List)
最后一个节点的 next 指向头节点,形成环形结构。
适用场景:
- 多人游戏轮流操作
- 操作系统任务调度
- 斐波那契堆实现
实现示例:
class CircularLinkedList:
def __init__(self):
self.head = None
def traverse(self, starting_point=None):
if starting_point is None:
starting_point = self.head
node = starting_point
while node is not None and (node.next != starting_point):
yield node
node = node.next
yield node
def print_list(self, starting_point=None):
nodes = []
for node in self.traverse(starting_point):
nodes.append(str(node))
print(" -> ".join(nodes))
使用:
a, b, c, d = Node("a"), Node("b"), Node("c"), Node("d")
a.next = b; b.next = c; c.next = d; d.next = a
circular_llist.head = a
circular_llist.print_list() # a -> b -> c -> d
circular_llist.print_list(b) # b -> c -> d -> a
注意:循环链表没有 None 结尾,遍历时需防止无限循环。
总结
通过本文,你已掌握以下关键内容:
- 链表是什么,以及何时使用它
- 如何使用
collections.deque实现队列和栈 - 如何从零实现自己的链表类,包括遍历、插入、删除等方法
- 双向链表和循环链表的概念及用途
链表虽不如 Python 列表常用,但在特定场景下(如频繁头尾操作、图结构、面试题)具有不可替代的优势。建议动手实践,加深理解!