Anish Singh Wali, Pankaj Kumar 2022-08-04
如今,并行处理(Parallel processing)正受到越来越多的关注。如果你还不了解并行处理,可以从维基百科中学习相关知识。随着 CPU 制造商在处理器中不断增加核心数量,编写并行代码已成为提升程序性能的一种绝佳方式。Python 引入了 multiprocessing 模块,使我们能够编写并行代码。要理解该模块的主要动机,我们需要先掌握一些并行编程的基础知识。阅读完本文后,希望你能对这一主题有所了解。
Python 多进程中的 Process、Queue 和 Lock
Python 的 multiprocessing 模块中包含大量用于构建并行程序的类。其中,三个最基本的类是 Process、Queue 和 Lock。这些类将帮助你构建并行程序。但在详细介绍它们之前,我们先从一段简单的代码开始。
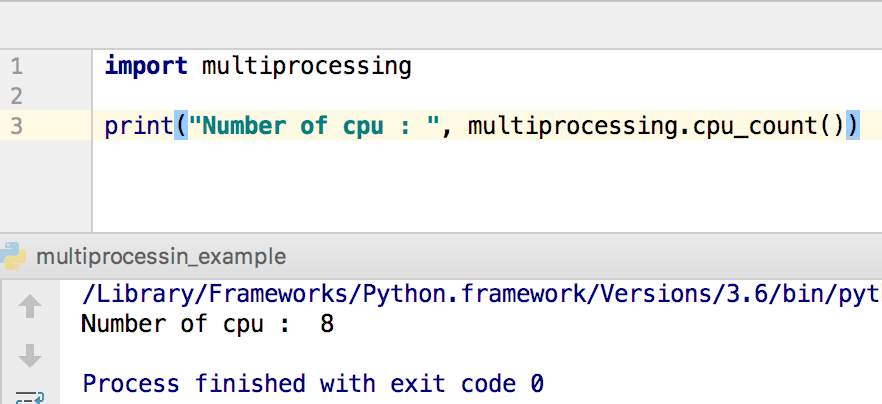
要让并行程序真正发挥作用,你需要知道你的电脑有多少个 CPU 核心。Python 的 multiprocessing 模块可以让你轻松获取这一信息。以下这段简单代码将打印出你电脑的 CPU 核心数量:
import multiprocessing
print("Number of cpu : ", multiprocessing.cpu_count())
以下输出结果会因你的电脑而异。以我为例,我的 CPU 核心数为 8。
Python multiprocessing 的 Process 类
Python multiprocessing 的 Process 类是一种抽象,它会启动另一个 Python 进程,让该进程运行指定代码,并提供一种方式让父应用程序控制其执行。
Process 类有两个重要的方法:start() 和 join()。
首先,我们需要编写一个函数,该函数将由子进程执行。然后,我们需要实例化一个 Process 对象。创建 Process 对象本身并不会立即执行任何操作,只有当我们调用 start() 方法时,进程才会真正开始运行并返回结果。之后,我们通过调用 join() 方法来等待该进程完成。
如果没有调用 join(),进程将保持空闲状态且不会终止。因此,如果你创建了许多进程但没有正确终止它们,可能会导致系统资源耗尽,甚至需要手动杀死这些进程。
另外需要注意的是:如果你想向目标函数传递参数,必须使用 args 关键字参数。
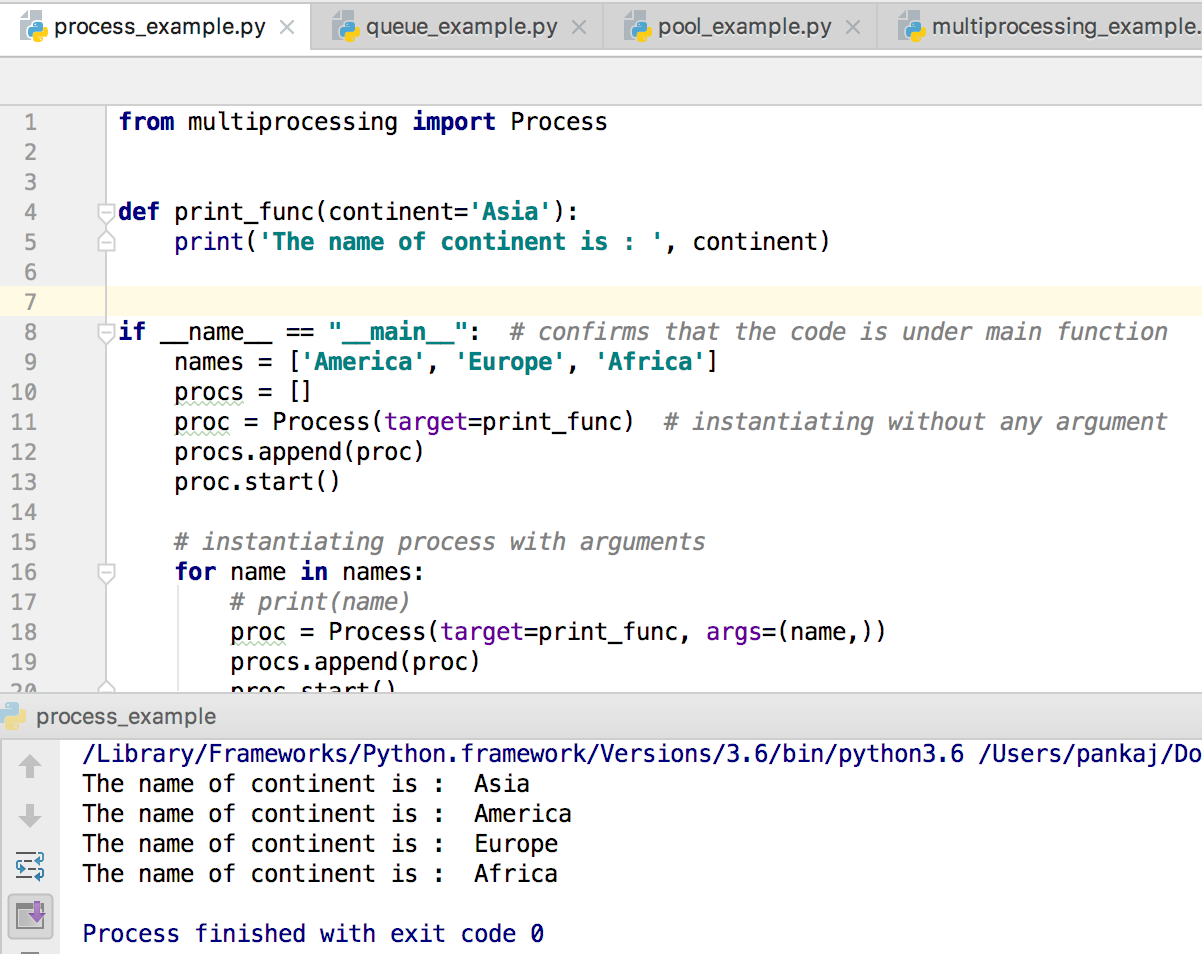
以下代码有助于理解 Process 类的用法:
from multiprocessing import Process
def print_func(continent='Asia'):
print('The name of continent is : ', continent)
if __name__ == "__main__": # 确保代码在主函数下运行
names = ['America', 'Europe', 'Africa']
procs = []
proc = Process(target=print_func) # 不带参数实例化
procs.append(proc)
proc.start()
# 带参数实例化进程
for name in names:
# print(name)
proc = Process(target=print_func, args=(name,))
procs.append(proc)
proc.start()
# 等待所有进程完成
for proc in procs:
proc.join()
上述代码的输出如下所示:
Python multiprocessing 的 Queue 类
如果你具备基本的计算机数据结构知识,你应该已经了解 队列(Queue)的概念。Python multiprocessing 模块提供的 Queue 类正是一个先进先出(FIFO)的数据结构。它可以存储任何可被 pickle 序列化的 Python 对象(尽管简单的对象效果最好),在多个进程之间共享数据时非常有用。
队列特别适用于作为参数传递给 Process 的 target 函数,以便该进程可以消费数据。我们可以使用 put() 方法向队列插入数据,使用 get() 方法从队列中取出数据。
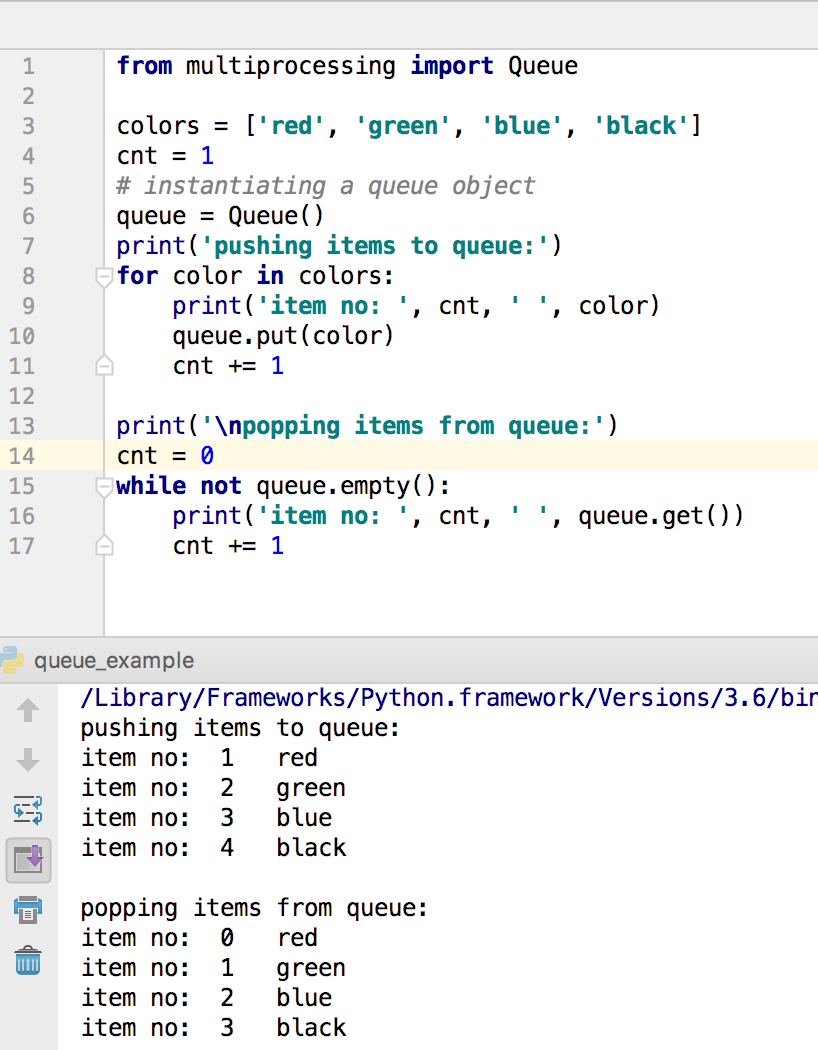
下面是一个快速示例:
from multiprocessing import Queue
colors = ['red', 'green', 'blue', 'black']
cnt = 1
# 实例化一个队列对象
queue = Queue()
print('pushing items to queue:')
for color in colors:
print('item no: ', cnt, ' ', color)
queue.put(color)
cnt += 1
print('\npopping items from queue:')
cnt = 0
while not queue.empty():
print('item no: ', cnt, ' ', queue.get())
cnt += 1
Python multiprocessing 的 Lock 类
Lock 类的任务非常简单:它允许某段代码获取锁,从而确保在该锁被释放之前,其他进程无法执行类似的代码。
因此,Lock 类主要有两个任务:
- 获取锁(使用 acquire() 方法)
- 释放锁(使用 release() 方法)
Python 多进程完整示例
在这个 Python 多进程示例中,我们将把前面学到的所有知识整合在一起。
假设我们有一些任务需要完成。为了完成这些任务,我们将使用多个进程。为此,我们会维护两个队列:
- 一个用于存放待处理的任务(
tasks_to_accomplish) - 另一个用于记录已完成任务的日志(
tasks_that_are_done)
然后我们实例化多个进程来完成这些任务。
注意:Python 的 Queue 类已经是线程安全和进程安全的(即内部已同步)。这意味着我们不需要再使用 Lock 类来防止多个进程同时访问同一个队列对象。因此,在本例中无需使用 Lock。
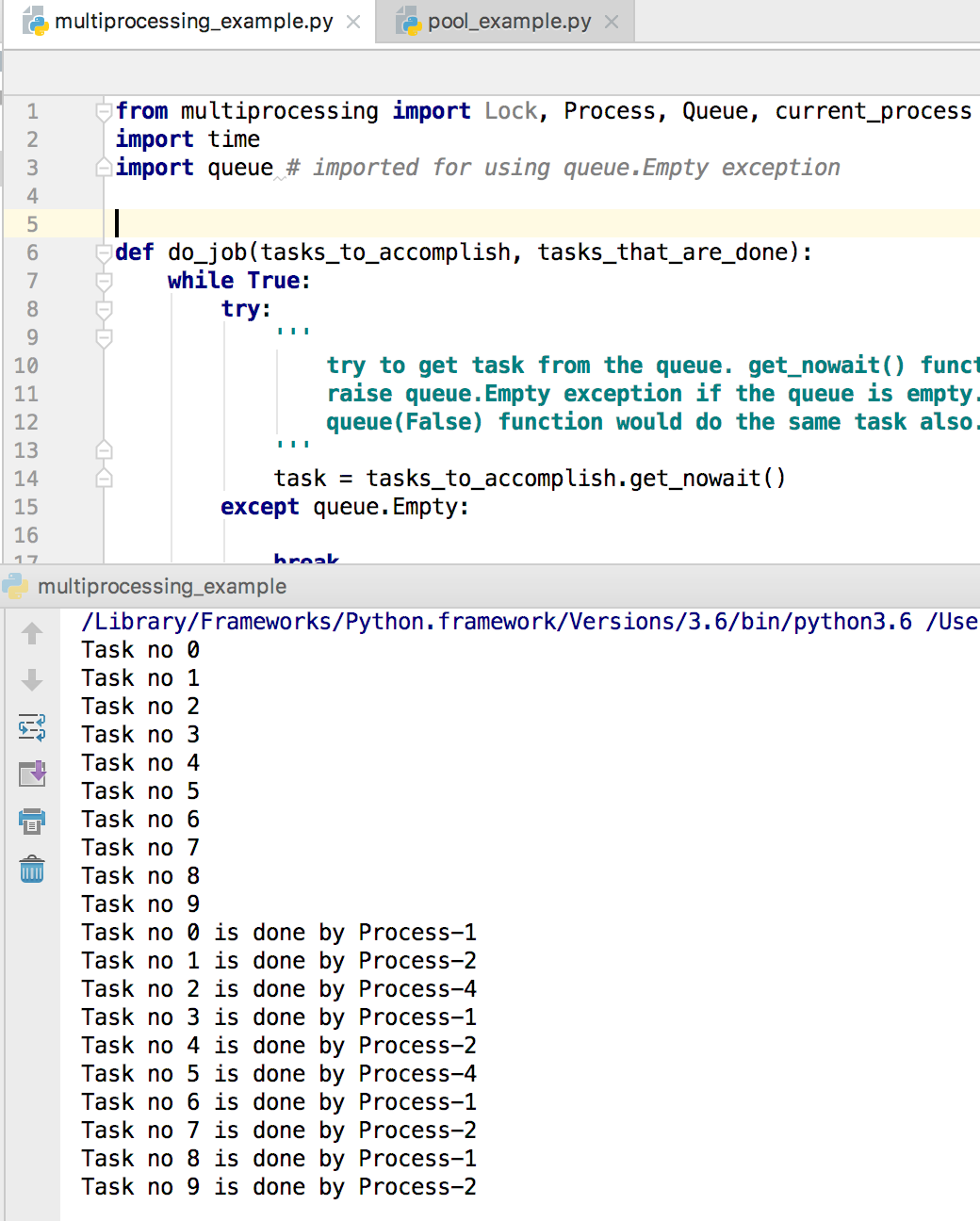
以下是完整实现:我们将任务添加到队列中,创建并启动多个进程,然后使用 join() 等待所有进程完成。最后,我们从第二个队列中打印出完成日志。
from multiprocessing import Lock, Process, Queue, current_process
import time
import queue # 导入 queue 模块以使用 queue.Empty 异常
def do_job(tasks_to_accomplish, tasks_that_are_done):
while True:
try:
'''
尝试从队列中获取任务。
get_nowait() 函数在队列为空时会抛出 queue.Empty 异常。
也可以使用 get(False) 实现相同功能。
'''
task = tasks_to_accomplish.get_nowait()
except queue.Empty:
break
else:
'''
如果没有抛出异常,则将任务完成信息
添加到 tasks_that_are_done 队列中
'''
print(task)
tasks_that_are_done.put(task + ' is done by ' + current_process().name)
time.sleep(.5)
return True
def main():
number_of_task = 10
number_of_processes = 4
tasks_to_accomplish = Queue()
tasks_that_are_done = Queue()
processes = []
for i in range(number_of_task):
tasks_to_accomplish.put("Task no " + str(i))
# 创建进程
for w in range(number_of_processes):
p = Process(target=do_job, args=(tasks_to_accomplish, tasks_that_are_done))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
# 打印输出结果
while not tasks_that_are_done.empty():
print(tasks_that_are_done.get())
return True
if __name__ == '__main__':
main()
根据任务数量的不同,这段代码可能需要一些时间才能显示输出。每次运行的输出顺序可能会有所不同。
Python multiprocessing 的 Pool(进程池)
Python multiprocessing 的 Pool 类可用于在多个输入值上并行执行某个函数,将输入数据分发到多个进程中(即数据并行)。
下面是一个简单的 Python multiprocessing Pool 示例:
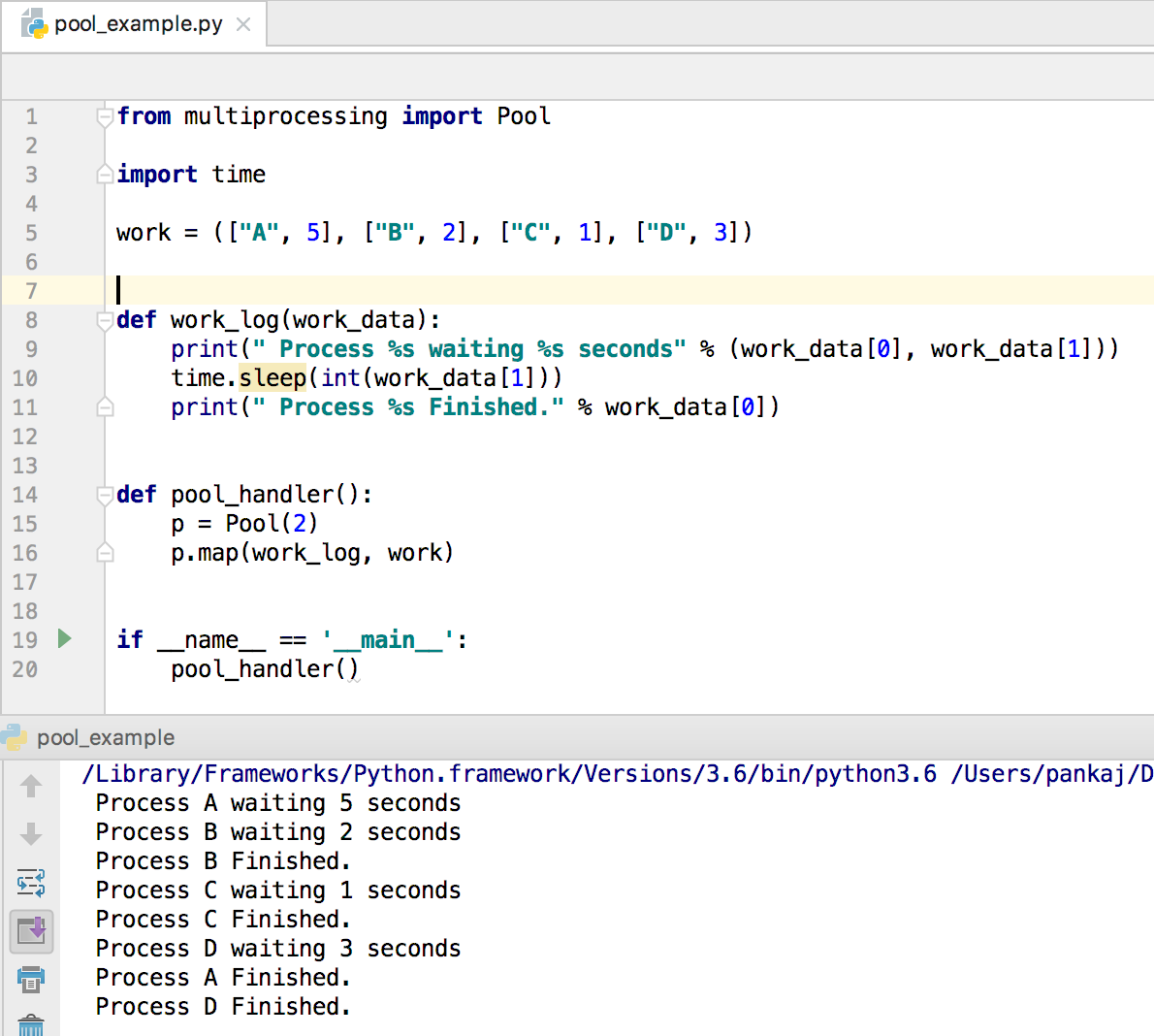
from multiprocessing import Pool
import time
work = (["A", 5], ["B", 2], ["C", 1], ["D", 3])
def work_log(work_data):
print(" Process %s waiting %s seconds" % (work_data[0], work_data[1]))
time.sleep(int(work_data[1]))
print(" Process %s Finished." % work_data[0])
def pool_handler():
p = Pool(2)
p.map(work_log, work)
if __name__ == '__main__':
pool_handler()
下图展示了上述程序的输出。注意,进程池大小为 2,因此 work_log 函数的两个实例会并行执行。当其中一个函数执行完成后,它会自动获取下一个待处理的任务,依此类推。
以上就是关于 Python multiprocessing 模块的全部内容。 参考:官方文档