引言
近年来,机器学习蓬勃发展。它正越来越多地融入我们的日常生活,并为各行各业的企业带来巨大的价值。普华永道(PwC)预测,到2030年,人工智能将为全球经济贡献15.7万亿美元。听起来好得令人难以置信……
然而,既然人工智能对全球经济和社会具有如此巨大的潜在价值,为什么我们却频繁听到一些AI系统灾难性失败的故事?而且这些故事往往来自一些规模最大、技术最先进的企业。
你肯定见过类似的新闻标题,比如亚马逊和苹果的招聘工具及信用卡服务存在性别偏见问题。这些问题不仅损害了各自公司的声誉,还可能对整个社会造成巨大的负面影响。此外,还有Zillow著名的iBuying算法——由于不可预测的市场事件,导致公司不得不将其房地产投资组合的价值减记5亿美元。
大约8年前,在TensorFlow、PyTorch和XGBoost等工具出现之前,数据科学界的主要关注点是如何实际构建和训练机器学习模型。随着上述工具及其他更多工具的出现,数据科学家们得以将理论付诸实践,开始构建机器学习模型以解决现实世界的问题。
在模型构建阶段的问题得到解决后,近年来的重点逐渐转向如何通过将模型投入生产来创造现实价值。像SageMaker、Databricks和Kubeflow这样的大型端到端平台在这方面做得非常出色,它们提供了灵活且可扩展的基础设施,用于部署机器学习模型,供更广泛的企业或公众使用。
如今,构建和部署机器学习所需的工具和基础设施已经齐备,企业将机器学习提供给外部客户或用于业务决策的门槛已大幅降低。因此,类似上述失败案例在未来更频繁发生的可能性也越来越大。
这正是机器学习验证(Machine Learning Validation)发挥作用的地方……
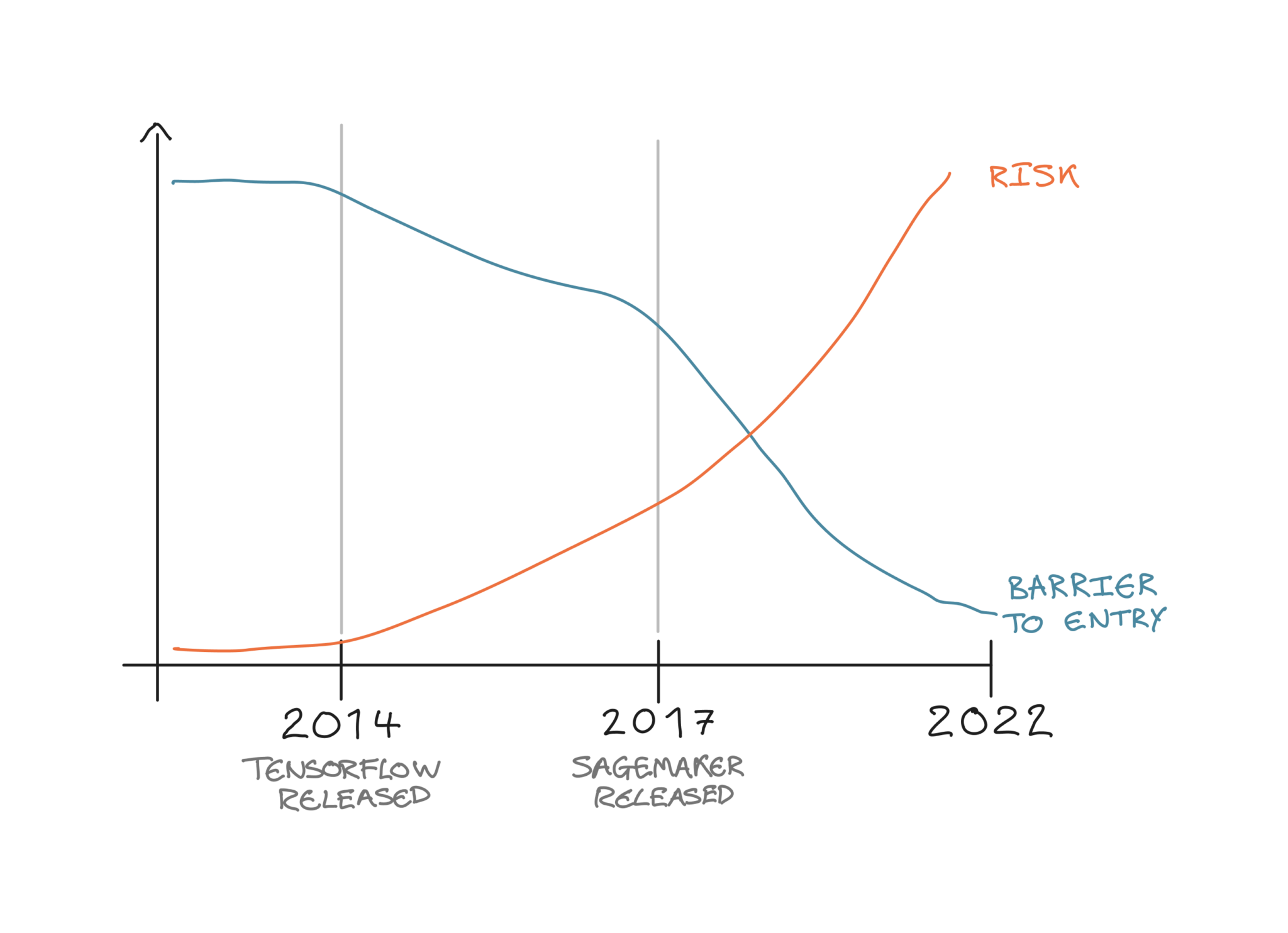 图1:过去8年AI/ML准入门槛与相关风险对比图。作者供图。
图1:过去8年AI/ML准入门槛与相关风险对比图。作者供图。
目录
- 引言
- 什么是机器学习验证?
- 机器学习验证的五个阶段
- 机器学习数据验证(ML Data Validations)
- 训练验证(Training Validations)
- 部署前验证(Pre-deployment Validations)
- 部署后验证(Post-deployment Validations)
- 治理与合规验证(Governance & Compliance Validations)
- 实施机器学习验证政策的好处
总结(TL;DR)
- 机器学习系统无法用传统的软件测试技术进行测试。
- 机器学习验证是评估机器学习系统质量的过程。
- 已识别出五种不同类型的机器学习验证:
- ML数据验证:评估用于训练和测试模型的数据质量。
- 训练验证:评估使用不同数据或参数训练的模型。
- 部署前验证:部署前的最终质量检查。
- 部署后验证:在生产环境中持续评估模型性能。
- 治理与合规验证:满足政府和组织的合规要求。
- 实施机器学习验证流程将确保ML系统高质量构建、合规,并被业务部门接受,从而提高采用率。
什么是机器学习验证?
由于机器学习的概率性本质,很难像传统软件那样对其进行测试(例如单元测试、集成测试等)。因为模型所依赖的数据及其运行环境会随时间频繁变化,仅针对特定结果测试模型并不是一种良好的实践。今天表现良好的模型,明天可能就完全错误。
此外,如果在模型或数据中发现错误,解决方案也不能仅仅是“打个补丁”。同样,这是由于机器学习模型所处环境不断变化,且需要重新训练。如果只是修复模型本身,那么下次模型重新训练或数据更新时,该修复就会丢失,不再生效。因此,应实施模型验证机制,以检查特定的模型行为和数据质量。
需要特别注意的是,本文所说的“验证”并非指机器学习生命周期中训练阶段通常进行的那种验证(如训练集/验证集划分)。我们这里所说的机器学习验证,是指在传统软件测试方法之外,对整个机器学习系统质量进行测试的过程。应在机器学习生命周期的各个阶段设置测试,既要在模型上线生产前验证其质量,也要在生产环境中持续监控系统健康状况,以检测任何潜在的性能退化。
机器学习验证的五个阶段
如下图2所示,已识别出机器学习验证的五个关键阶段:
- ML数据验证(ML Data Validations)
- 训练验证(Training Validations)
- 部署前验证(Pre-deployment Validations)
- 部署后验证(Post-deployment Validations)
- 治理与合规验证(Governance & Compliance Validations)
本文剩余部分将逐一深入解析每个阶段,包括其定义、验证类型及具体示例。
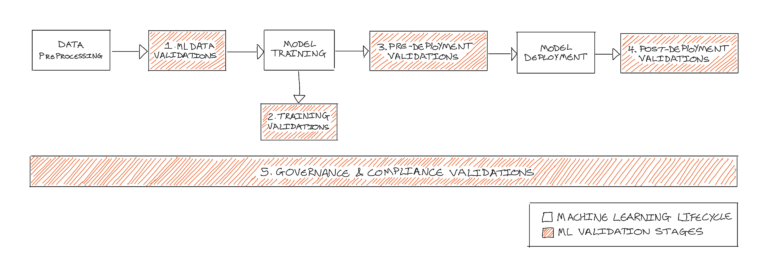 图2:示意图展示机器学习验证的五个阶段如何嵌入典型的机器学习生命周期中。作者供图。
图2:示意图展示机器学习验证的五个阶段如何嵌入典型的机器学习生命周期中。作者供图。
1. ML数据验证(ML Data Validations)
近年来,业界出现了向以数据为中心的机器学习开发(data-centric ML development)的重大转变,这凸显了使用高质量数据训练模型的重要性。机器学习模型根据其训练数据学习如何预测特定结果。因此,如果训练数据不能很好地代表目标状态,模型就会给出糟糕的预测。简而言之:垃圾进,垃圾出(Garbage in, garbage out)。
数据验证用于评估用于训练和测试模型的数据集质量。可分为两个子类别:
- 数据工程验证(Data Engineering Validations):基于基本理解和规则,识别数据集中的通用问题。例如,检查数据中是否存在空列或NaN值,以及特征值是否在已知范围内。例如,确认“年龄”(Age)这一特征的值应在0–100之间。
- 基于ML的数据验证(ML-based Data Validations):评估数据是否适合训练机器学习模型。例如,确保数据集分布均衡,避免模型产生偏见,或在某些特征或取值上表现远优于其他情况。
如图3所示,最佳实践是在进入机器学习流水线之前完成数据工程验证。因此,只有基于ML的数据验证才应在机器学习流水线内部执行。
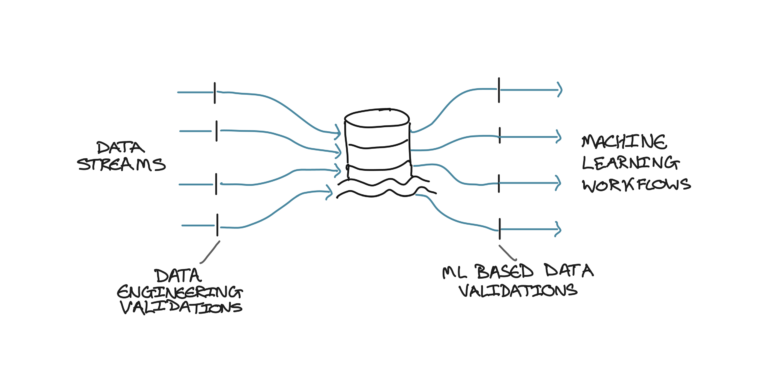 图3:示意图展示两种不同类型的数据验证在数据处理流程中的位置。作者供图。
图3:示意图展示两种不同类型的数据验证在数据处理流程中的位置。作者供图。
2. 训练验证(Training Validations)
训练验证是指需要重新训练模型的任何验证。通常包括在单次训练任务中测试不同模型。这些验证在模型开发的训练/评估阶段进行,通常作为实验代码保留,不会进入最终的生产版本。
训练验证在实践中的一些应用示例包括:
- 超参数优化(Hyperparameter Optimisation):常使用网格搜索(Grid Search)等技术寻找最佳超参数组合,但很少对其进行验证。一个简单的验证方法是:比较经过超参数优化的模型与使用固定超参数集的模型的性能。还可以增加复杂度,例如测试调整单个超参数是否对模型性能产生预期影响。
- 交叉验证(Cross-validation):在不同数据划分上进行训练,可转化为验证。例如,验证每个模型的性能输出是否在给定范围内,以确保模型具有良好泛化能力。
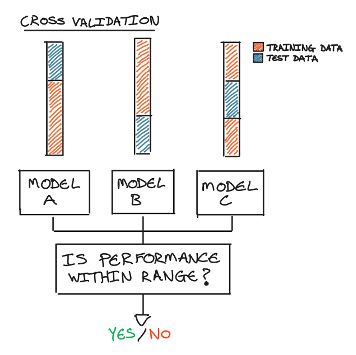 图4:示例展示如何将交叉验证转化为简单验证。作者供图。
图4:示例展示如何将交叉验证转化为简单验证。作者供图。
- 特征选择验证(Feature Selection Validations):在整个模型生命周期中,应持续评估某些特征的重要性和影响力。例如,从训练集中移除某些特征,或添加随机噪声特征,以验证这对性能指标(如准确率)或特征重要性的影响。
3. 部署前验证(Pre-deployment Validations)
模型训练完成后并选定最终模型后,应在训练验证流程之外,对其性能和行为进行最终验证。这涉及围绕可衡量指标创建可操作的测试。例如,重新确认性能指标是否高于某个阈值。
评估模型性能时,通常会查看准确率、精确率、召回率、F1分数或自定义评估指标等。但我们还可以更进一步:在数据集的不同切片上评估这些指标。例如,对于一个简单的房价回归模型,模型在预测两居室和五居室房屋价格时的表现有何差异?这类信息很少向模型用户披露,但对理解模型的优势和弱点极具参考价值,有助于建立对模型的信任。
 图5:示例展示如何将简单的模型性能指标(如准确率)进一步拆解,以验证不同数据切片上的表现。作者供图。
图5:示例展示如何将简单的模型性能指标(如准确率)进一步拆解,以验证不同数据切片上的表现。作者供图。
其他性能验证还包括:
- 将模型与随机基线模型进行比较,确保模型确实从数据中学习到了规律;
- 在低延迟应用场景中,测试模型推理时间是否低于某个阈值。
除了性能验证外,还可包含其他类型的验证:
- 鲁棒性验证:通过检查单个边缘案例,或验证模型在最小数据集上的预测准确性;
- 可解释性验证:例如,检查某个特征是否位于前N个最重要特征之中。
需要再次强调的是,所有这些部署前验证都基于可衡量的指标,并将其转化为通过/失败(pass/fail)的测试。这些验证是模型投入生产前的最后一道“放行/否决”关卡,因此是一种预防性措施,确保即将用于业务决策的模型具备高质量和透明性。
4. 部署后验证(Post-deployment Validations,即模型监控)
一旦模型通过部署前验证,就会被推送到生产环境。由于模型此时正在做出实时决策,部署后验证用于持续检查模型健康状况,确认其仍适合在生产环境中使用。因此,部署后验证是一种反应性措施。
机器学习模型基于历史训练数据进行预测,即使模型周围环境发生微小变化,也可能导致预测结果严重错误。模型监控(Model Monitoring)已成为行业广泛采用的实践,用于计算实时模型指标,例如滚动性能指标,或比较线上数据与训练数据的分布。
与部署前验证类似,部署后验证是将这些监控指标转化为可操作的测试。通常涉及告警机制。例如,如果实时准确率指标低于某个阈值,系统会发送告警,触发某些操作,如通知数据科学团队,或调用API启动重新训练流水线。
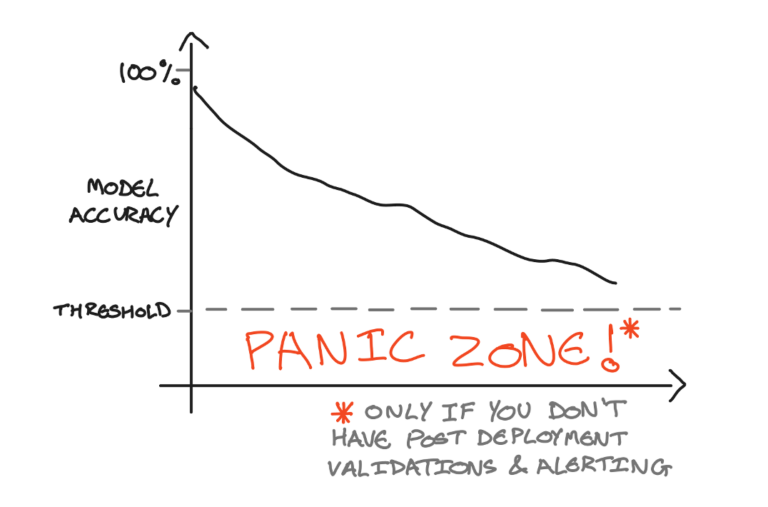 图6:示意图展示模型性能随时间衰减的情况,以及如何设置阈值以触发操作。作者供图。
图6:示意图展示模型性能随时间衰减的情况,以及如何设置阈值以触发操作。作者供图。
部署后验证包括:
- 滚动性能计算(Rolling Performance Calculations):如果机器学习系统能够获取预测结果是否正确的反馈,则可实时计算性能指标。然后将实时性能与训练性能进行比较,确保其在一定阈值内且未持续下降。
- 异常检测(Outlier Detection):通过分析模型训练数据的分布,可在实时请求中检测异常值。例如,若新请求中包含“Age=105”,而训练数据中“年龄”范围为0–100,则该值会被标记为异常。
- 漂移检测(Drift Detection):用于识别模型周围环境是否发生变化。常用技术是比较线上数据与训练数据的分布,并检查其差异是否在阈值内。仍以“年龄”为例,如果线上输入突然大量出现Age>100的请求,线上数据分布的中位数将高于训练数据。若该差异超过阈值,则判定为发生漂移。
- A/B测试(A/B Testing):在将新模型版本推送到生产环境前,或为了找出在真实数据上表现最佳的模型,可使用A/B测试。A/B测试将一部分流量导向模型A,另一部分导向模型B,通过选定的性能指标评估各模型表现,选择更优者并全面推广。
5. 治理与合规验证(Governance & Compliance Validations)
让模型在生产环境中运行并确保其预测高质量固然重要,但确保模型以公平、合规的方式做出预测同样重要(甚至更重要)。这包括遵守监管机构制定的法规,以及符合组织自身的价值观。
正如引言所述,近期新闻报道显示,全球一些最大型企业在这方面频频出错,将带有偏见或歧视性的机器学习模型引入现实世界。
《通用数据保护条例》(GDPR)、《欧盟人工智能法案》(EU Artificial Intelligence Act)和GxP等法规正在制定相关政策,以确保组织以安全、公平的方式使用机器学习。
这些政策包括:
- 理解并识别AI系统的风险等级(分为不可接受风险、高风险、有限及最低风险);
- 确保个人身份信息(PII)未被不当存储或使用;
- 确保不使用性别、种族、宗教等受保护特征;
- 确认模型训练所用数据的新鲜度;
- 确认模型定期重新训练并保持最新状态,且具备充分的再训练流程。
组织应制定自己的AI/ML合规政策,使其既符合官方政府AI/ML合规法案,又契合公司价值观。这将确保在开发任何机器学习系统时,都具备必要的流程和保障措施。
这一验证阶段贯穿于上述所有其他验证阶段。建立适当的ML验证流程,将提供一个框架,用于报告模型在每个阶段是如何被验证的,从而满足合规要求。
实施机器学习验证政策的好处
在机器学习流水线的全部五个阶段实施适当的验证流程,将确保:
- 机器学习系统从构建到运行始终保持高质量;
- 系统完全合规且安全可用;
- 所有利益相关方都能清晰了解模型的验证方式及其带来的价值。
企业应确保建立正确的流程和政策,以验证其技术团队交付的机器学习成果。同时,数据科学团队应在机器学习系统规划阶段就纳入验证设计。这将明确模型必须通过哪些测试才能上线并持续留在生产环境中。
这不仅能确保企业从其机器学习系统中获得巨大价值,还能让非技术业务用户和利益相关方对所交付的机器学习应用建立信任,从而推动机器学习在整个组织内的广泛采用。