Murilo Gustineli 2024-09-26
揭开 NLP 的神秘面纱:从文本到嵌入(Embeddings)
 由 Llama-3-8B 生成的分词示例。每个彩色子词代表一个独立的 token(标记)。
由 Llama-3-8B 生成的分词示例。每个彩色子词代表一个独立的 token(标记)。
什么是分词(Tokenization)?
在计算机科学中,我们将英语、中文等人类语言称为“自然”语言。相比之下,汇编语言(Assembly)和 LISP 等用于与计算机交互的语言被称为“机器”语言,它们遵循严格的语法规则,几乎没有解释空间。虽然计算机擅长处理自身高度结构化的语言,但在面对人类语言的混乱性时却显得力不从心。
语言——尤其是文本——构成了我们大部分的沟通和知识存储方式。例如,互联网主要由文本组成。像 ChatGPT、Claude 和 Llama 这样的大语言模型是在海量文本上训练而成的——基本上涵盖了网络上所有可用的文本——并使用了复杂的计算技术。然而,计算机处理的是数字,而不是单词或句子。那么,我们如何弥合人类语言与机器理解之间的鸿沟呢?
这正是自然语言处理(NLP)发挥作用的地方。NLP 是一门融合了语言学、计算机科学和人工智能的领域,旨在使计算机能够理解、解释并生成人类语言。无论是将英文翻译成法文、总结文章,还是进行对话,NLP 都能让机器从文本输入中产生有意义的输出。
NLP 中的第一个关键步骤是将原始文本转换为计算机能够有效处理的格式。这一过程被称为分词(tokenization)。分词涉及将文本拆分为更小、更易管理的单元,称为token(标记),这些标记可以是单词、子词,甚至是单个字符。该过程通常包括以下步骤:
- 标准化(Standardization):在分词之前,对文本进行标准化以确保一致性。这可能包括将所有字母转换为小写、删除标点符号,以及应用其他规范化技术。
- 分词(Tokenization):将标准化后的文本拆分为标记。例如,句子 “The quick brown fox jumps over the lazy dog” 可以按单词分词为:
["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"] - 数值表示(Numerical representation):由于计算机处理的是数值数据,因此每个标记都会被转换为数值表示形式。这种转换可以简单到为每个标记分配一个唯一标识符,也可以复杂到创建多维向量来捕捉标记的含义和上下文。
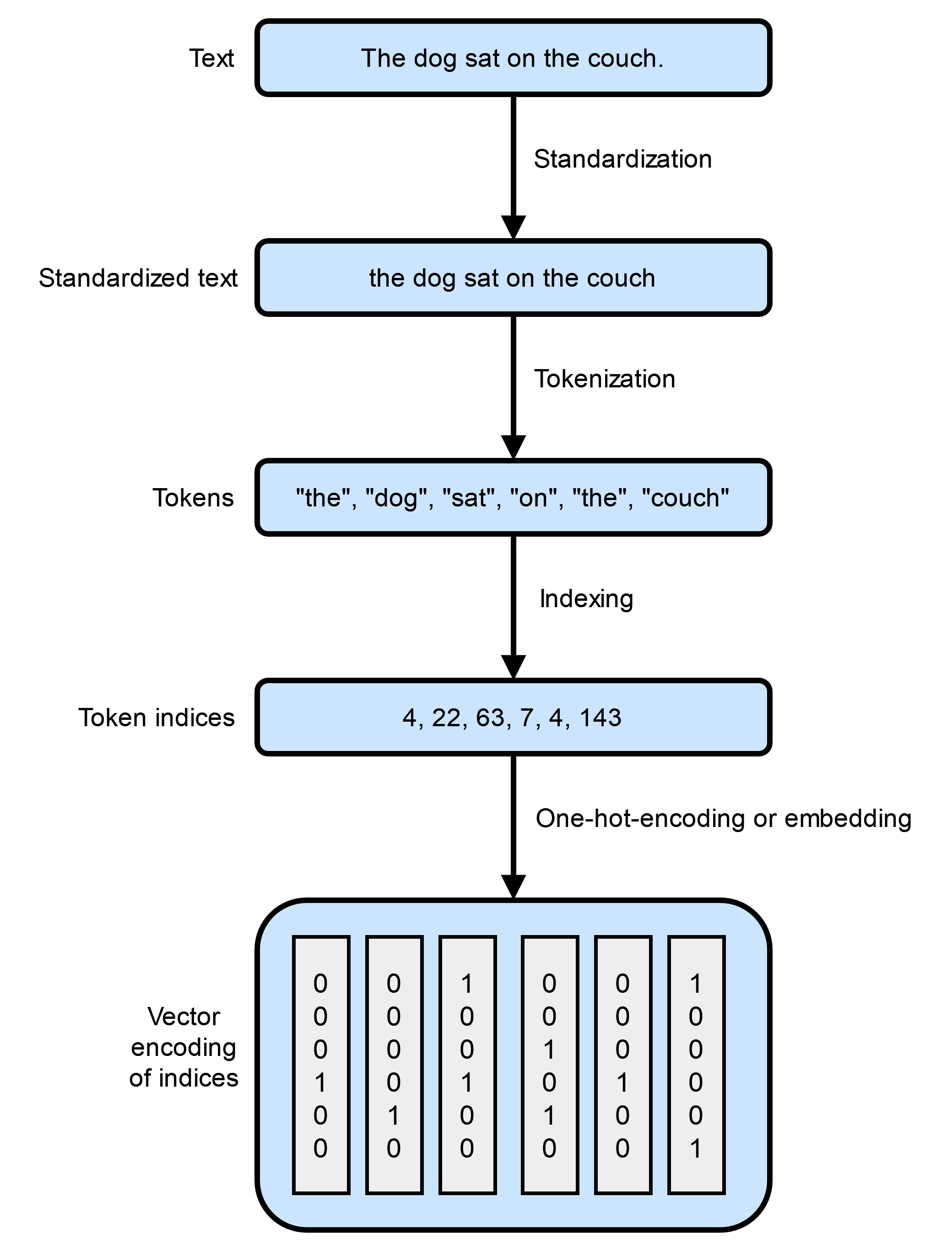 插图灵感源自 François Chollet 所著《Python 深度学习》中的 “图 11.1 从文本到向量”
插图灵感源自 François Chollet 所著《Python 深度学习》中的 “图 11.1 从文本到向量”
分词不仅仅是拆分文本;它更是以一种保留语义和上下文的方式为计算模型准备语言数据。不同的分词方法会显著影响模型理解和处理语言的效果。
在本文中,我们将重点讨论文本标准化和分词,探索几种技术和实现方式。我们将为将文本转换为机器可处理的数值形式奠定基础——这是迈向词嵌入(word embeddings)和语言建模等高级主题的关键一步,我们将在未来的文章中深入探讨这些内容。
文本标准化(Text Standardization)
考虑以下两个句子:
"dusk fell, i was gazing at the Sao Paulo skyline. Isnt urban life vibrant??""Dusk fell; I gazed at the São Paulo skyline. Isn't urban life vibrant?"
乍看之下,这两个句子传达的意思相似。然而,在由计算机处理时(尤其是在分词或编码任务中),由于细微差异,它们可能会显得截然不同:
- 大小写:“dusk” vs. “Dusk”
- 标点符号:逗号 vs. 分号;问号的存在
- 缩写形式:“Isnt” vs. “Isn't”
- 拼写和特殊字符:“Sao Paulo” vs. “São Paulo”
这些差异会显著影响算法对文本的解读。例如,“Isnt” 缺少撇号可能不会被识别为 “is not” 的缩写形式,而 “São” 中的特殊字符 “ã” 可能会被误解或导致编码问题。
文本标准化是 NLP 中至关重要的预处理步骤,用于解决这些问题。通过标准化文本,我们可以减少无关的变异性,并确保输入模型的数据具有一致性。这一过程是一种特征工程形式,我们在此过程中消除了对当前任务无意义的差异。
一种简单的文本标准化方法包括:
- 转为小写:减少因大小写造成的差异。
- 删除标点符号:通过移除标点符号简化文本。
- 规范化特殊字符:将 “ã” 等字符转换为其标准形式(如 “a”)。
对上述两个句子应用这些步骤后,我们得到:
"dusk fell i was gazing at the sao paulo skyline isnt urban life vibrant""dusk fell i gazed at the sao paulo skyline isnt urban life vibrant"
现在,这两个句子更加统一,仅突出了有意义的用词差异(例如,“was gazing at” 与 “gazed at”)。
虽然还有更高级的标准化技术,如词干提取(stemming)(将单词还原为其词根形式)和词形还原(lemmatization)(将单词还原为其字典形式),但这种基本方法已能有效减少表面差异。
Python 实现文本标准化
以下是使用 Python 实现基本文本标准化的方法:
import re
import unicodedata
def standardize_text(text: str) -> str:
# 转换为小写
text = text.lower()
# 将 Unicode 字符标准化为 ASCII
text = unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8')
# 删除标点符号
text = re.sub(r'[^w\s]', '', text)
# 删除多余空格
text = re.sub(r'\s+', ' ', text).strip()
return text
# 示例句子
sentence1 = "dusk fell, i was gazing at the Sao Paulo skyline. Isnt urban life vibrant??"
sentence2 = "Dusk fell; I gazed at the São Paulo skyline. Isn't urban life vibrant?"
# 标准化句子
std_sentence1 = standardize_text(sentence1)
std_sentence2 = standardize_text(sentence2)
print(std_sentence1)
print(std_sentence2)
输出:
dusk fell i was gazing at the sao paulo skyline isnt urban life vibrant
dusk fell i gazed at the sao paulo skyline isnt urban life vibrant
通过标准化文本,我们最小化了可能混淆计算模型的差异。现在,模型可以专注于句子之间的真正差异,例如 “was gazing at” 与 “gazed at”,而不是标点或大小写等无关差异。
分词(Tokenization)
在文本标准化之后,自然语言处理中的下一个关键步骤是分词(tokenization)。分词涉及将标准化后的文本拆分为称为**标记(tokens)的更小单元。这些标记是模型用于理解和生成人类语言的基本构件。分词为向量化(vectorization)**做准备,在向量化过程中,每个标记都会被转换为机器可处理的数值表示形式。
我们的目标是将句子转换为计算机能够高效且有效地处理的形式。常见的分词方法有三种:
1. 词级分词(Word-level tokenization)
根据空格和标点将文本拆分为单个单词。这是最直观的文本拆分方式。
text = "dusk fell i gazed at the sao paulo skyline isnt urban life vibrant"
tokens = text.split()
print(tokens)
输出:
['dusk', 'fell', 'i', 'gazed', 'at', 'the', 'sao', 'paulo', 'skyline', 'isnt', 'urban', 'life', 'vibrant']
2. 字符级分词(Character-level tokenization)
将文本拆分为单个字符,包括字母,有时也包括标点符号。
text = "Dusk fell"
tokens = list(text)
print(tokens)
输出:
['D', 'u', 's', 'k', ' ', 'f', 'e', 'l', 'l']
3. 子词分词(Subword tokenization)
将单词拆分为更小的、有意义的子词单元。这种方法在字符级分词的粒度和词级分词的语义丰富性之间取得平衡。字节对编码(Byte-Pair Encoding, BPE)和 WordPiece 等算法属于此类。例如,BertTokenizer 会将 “I have a new GPU!” 分词如下:
from transformers import BertTokenizer
text = "I have a new GPU!"
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize(text)
print(tokens)
输出:
['i', 'have', 'a', 'new', 'gp', '##u', '!']
在这里,“GPU” 被拆分为 “gp” 和 “##u”,其中 “##” 表示 “u” 是前一个子词的延续。
子词分词在词汇表大小和语义表示之间取得了良好平衡。通过将罕见词分解为常见子词,它在保持可控词汇表大小的同时不牺牲语义。子词携带语义信息,有助于模型更有效地理解上下文。这意味着模型可以通过将新词或罕见词拆解为熟悉的子词来处理更广泛的输入语言。
例如,考虑单词 “annoyingly”,它在训练语料库中可能很罕见。它可以被分解为子词 “annoying” 和 “ly”。这两个子词各自出现频率更高,其组合含义仍保留了 “annoyingly” 的本质。这种方法在土耳其语等黏着语中尤其有益,因为在这些语言中,单词可以通过串联子词变得极长,以表达复杂含义。
请注意,标准化步骤通常已集成到分词器本身中。大语言模型在处理文本时,既将 token 作为输入,也将其作为输出。以下是 Llama-3–8B 在 Tiktokenizer 上生成的 token 可视化表示:
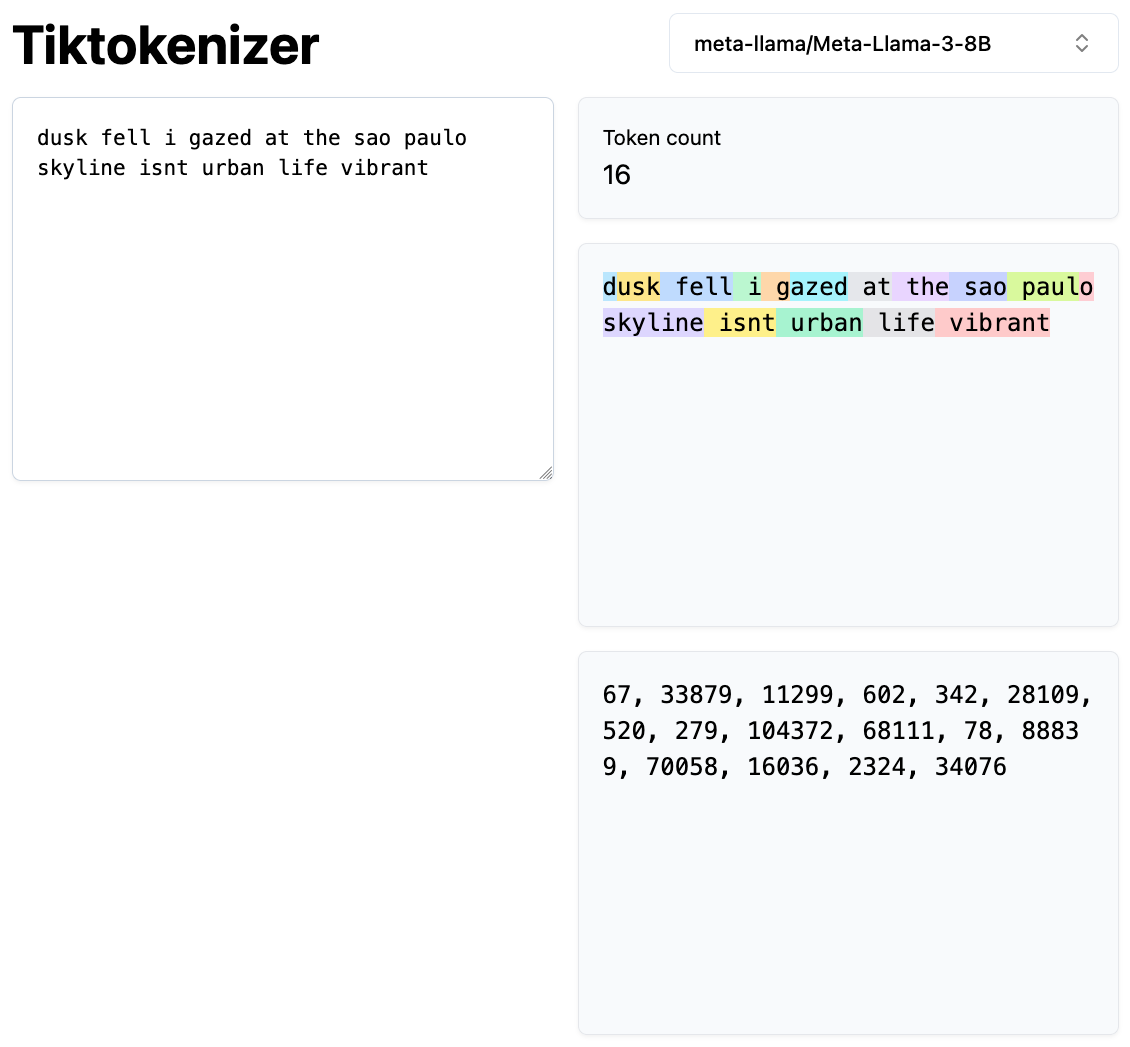 Tiktokenizer 使用 Llama-3–8B 的示例。每个 token 以不同颜色表示。
Tiktokenizer 使用 Llama-3–8B 的示例。每个 token 以不同颜色表示。
此外,Hugging Face 提供了一份优秀的 分词器指南,我在本文中使用了其中的一些示例。
接下来,我们将探讨不同子词分词算法的工作原理。需要注意的是,所有这些分词算法都依赖某种形式的训练,通常是在对应模型将要训练的语料库上完成的。
字节对编码(Byte-Pair Encoding, BPE)
字节对编码(BPE)是一种子词分词方法,由 Sennrich 等人在 2015 年发表的论文《Neural Machine Translation of Rare Words with Subword Units》中提出。BPE 从一个基础词汇表开始,该词汇表包含训练数据中所有唯一的字符,并迭代地合并出现频率最高的符号对(可以是字符或字符序列)以形成新的子词。此过程持续进行,直到词汇表达到预定义的大小(这是一个你在训练前选择的超参数)。
假设我们有以下单词及其出现频率:
- "hug"(出现 10 次)
- "pug"(5 次)
- "pun"(12 次)
- "bun"(4 次)
- "hugs"(5 次)
我们的初始基础词汇表包含以下字符:["h", "u", "g", "p", "n", "b", "s"]。
我们将单词拆分为单个字符:
- "h" "u" "g"(hug)
- "p" "u" "g"(pug)
- "p" "u" "n"(pun)
- "b" "u" "n"(bun)
- "h" "u" "g" "s"(hugs)
接下来,我们统计每个符号对的频率:
- "h u":15 次(来自 "hug" 和 "hugs")
- "u g":20 次(来自 "hug"、"pug"、"hugs")
- "p u":17 次(来自 "pug"、"pun")
- "u n":16 次(来自 "pun"、"bun")
出现频率最高的对是 "u g"(20 次),因此我们将 "u" 和 "g" 合并为 "ug",并更新单词:
- "h" "ug"(hug)
- "p" "ug"(pug)
- "p" "u" "n"(pun)
- "b" "u" "n"(bun)
- "h" "ug" "s"(hugs)
我们继续这一过程,合并下一个最频繁的对(如将 "u n" 合并为 "un"),直到达到所需的词汇表大小。
BPE 通过指定合并操作的数量来控制词汇表大小。常见词保持完整,减少了大量记忆的需求;而罕见词或未见过的词则可以通过已知子词的组合来表示。该方法被 GPT 和 RoBERTa 等模型所采用。
Hugging Face 的 tokenizers 库提供了一种快速灵活的方式来训练和使用分词器,包括 BPE。
训练一个 BPE 分词器
以下是如何在样本数据集上训练 BPE 分词器的方法:
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
# 初始化分词器
tokenizer = Tokenizer(BPE())
# 设置预分词器为按空格分割
tokenizer.pre_tokenizer = Whitespace()
# 初始化训练器,指定词汇表大小
trainer = BpeTrainer(vocab_size=1000, min_frequency=2, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
# 要训练的文件
files = ["path/to/your/dataset.txt"]
# 训练分词器
tokenizer.train(files, trainer)
# 保存分词器
tokenizer.save("bpe-tokenizer.json")
使用训练好的 BPE 分词器
from tokenizers import Tokenizer
# 加载分词器
tokenizer = Tokenizer.from_file("bpe-tokenizer.json")
# 编码文本输入
encoded = tokenizer.encode("I have a new GPU!")
print("Tokens:", encoded.tokens)
print("IDs:", encoded.ids)
输出:
Tokens: ['I', 'have', 'a', 'new', 'GP', 'U', '!']
IDs: [12, 45, 7, 89, 342, 210, 5]
WordPiece
WordPiece 是另一种子词分词算法,由 Schuster 和 Nakajima 在 2012 年提出,并因 BERT 等模型而广为人知。与 BPE 类似,WordPiece 也从所有唯一字符开始,但在选择要合并的符号对时有所不同。
WordPiece 的工作方式如下:
- 初始化:从所有唯一字符的词汇表开始。
- 预分词:将训练文本拆分为单词。
- 构建词汇表:迭代地向词汇表中添加新符号(子词)。
- 选择标准:与 BPE 选择最频繁的符号对不同,WordPiece 选择在加入词汇表后能最大化训练数据似然度的符号对。
使用与之前相同的词频,WordPiece 会评估哪个符号对在合并后能最大程度提高训练数据的概率。这涉及比 BPE 基于频率的方法更概率化的方法。
与 BPE 类似,我们也可以使用 tokenizers 库训练 WordPiece 分词器。
训练 WordPiece 分词器
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.trainers import WordPieceTrainer
from tokenizers.pre_tokenizers import Whitespace
# 初始化分词器
tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))
# 设置预分词器
tokenizer.pre_tokenizer = Whitespace()
# 初始化训练器
trainer = WordPieceTrainer(vocab_size=1000, min_frequency=2, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
# 训练分词器
tokenizer.train(files, trainer)
# 保存分词器
tokenizer.save("wordpiece-tokenizer.json")
使用训练好的 WordPiece 分词器
from tokenizers import Tokenizer
# 加载分词器
tokenizer = Tokenizer.from_file("wordpiece-tokenizer.json")
# 编码文本输入
encoded = tokenizer.encode("I have a new GPU!")
print("Tokens:", encoded.tokens)
print("IDs:", encoded.ids)
输出:
Tokens: ['I', 'have', 'a', 'new', 'G', '##PU', '!']
IDs: [10, 34, 5, 78, 301, 502, 8]
结论
分词是 NLP 中的基础步骤,它为计算模型准备文本数据。通过理解和实施适当的分词策略,我们使模型能够更有效地处理和生成人类语言,为词嵌入和语言建模等高级主题奠定基础。
本文中的所有代码也可在我的 GitHub 仓库中找到:github.com/murilogustineli/nlp-medium