Vaibhav Mehra 2025-08-28
自注意力机制简介
注意力机制(更具体地说,是自注意力机制)最早由 Vaswani 等人在 2017 年发表的著名论文《Attention is All You Need》中提出。
这一机制正是 Transformer 模型的核心动力,而 Transformer 又支撑着当今一些最强大的模型,例如大语言模型(LLMs)和视觉-语言模型(VLMs)。
所以,它确实非常重要!
但这里有个关键点:许多人(包括我过去也是其中之一!)认为注意力机制是在 2017 年才被发明的。
事实并非如此。
最初的注意力机制早在 2015 年就已出现,当时 Bahdanau 等人在机器翻译的背景下首次引入了它。他们的想法是让解码器在每一步解码时,能够关注输入句子的不同部分,而不是依赖一个固定的上下文向量。
这一小小的改变带来了巨大的提升——也为后来的自注意力机制乃至多头注意力机制埋下了种子。
但你可能会问:
“注意力到底是什么意思?”
让我用两个简单的句子来解释这个概念:
- “The cat sat on the mat.”(猫坐在垫子上。)→ 我们的模型可能会让 sat 对 cat 和 mat 都产生注意力。
- “She drank her tea because she was thirsty.”(她喝茶是因为她口渴了。)→ drank 的注意力会指向 tea 和 thirsty,从而连接起因果关系与动作。
从这些例子中,我们可以初步理解注意力试图做什么:它关乎“聚焦” ——帮助模型判断在处理某个词时,哪些其他词是相关的,通常基于语义含义或语法关系。

需要注意的是,在计算注意力权重和分数时(稍后会详细说明),所有 token 都会被使用,而不仅仅是某些特定的 token,如上图所示。这也意味着某些词之间的注意力会比其他词更强,如图中箭头的粗细所表示。
这正是 Transformer 在理解语言方面如此出色的原因:它们利用注意力机制动态地将每个词与其他所有词关联起来。
中间步骤
现在我们已经了解了注意力是什么,但仍不清楚其内部是如何处理的。
这就是 查询(Query)、键(Key)和值(Value)(通常简写为 Q、K、V)发挥作用的地方。在本文剩余部分,我们将继续使用例句:“the cat sat on the mat”。
首先,当一个句子输入到 Transformer 中时,它会立即被分词器(tokenizer)进行分词,著名的分词方法之一是字节对编码(Byte-pair encoding, BPE)。
我们可以把分词看作是将文本拆分为更小的单元。由于我们例句中的单词都很短,为简化起见,我们可以假设每个单元就是一个单词。从视觉上看,经过分词器处理后的句子应如下所示:

请注意,连标点符号(句号)也被转换成了一个 token。同样,为简化起见,我们假设句号是一个独立的 token。
分词之后,我们使用分词器的词汇表(tokenizer vocabulary)将每个 token 转换为其对应的 Token ID。可以将这个词汇表理解为一个数据库或表格,其中包含模型能识别的所有 token 及其对应的 ID。
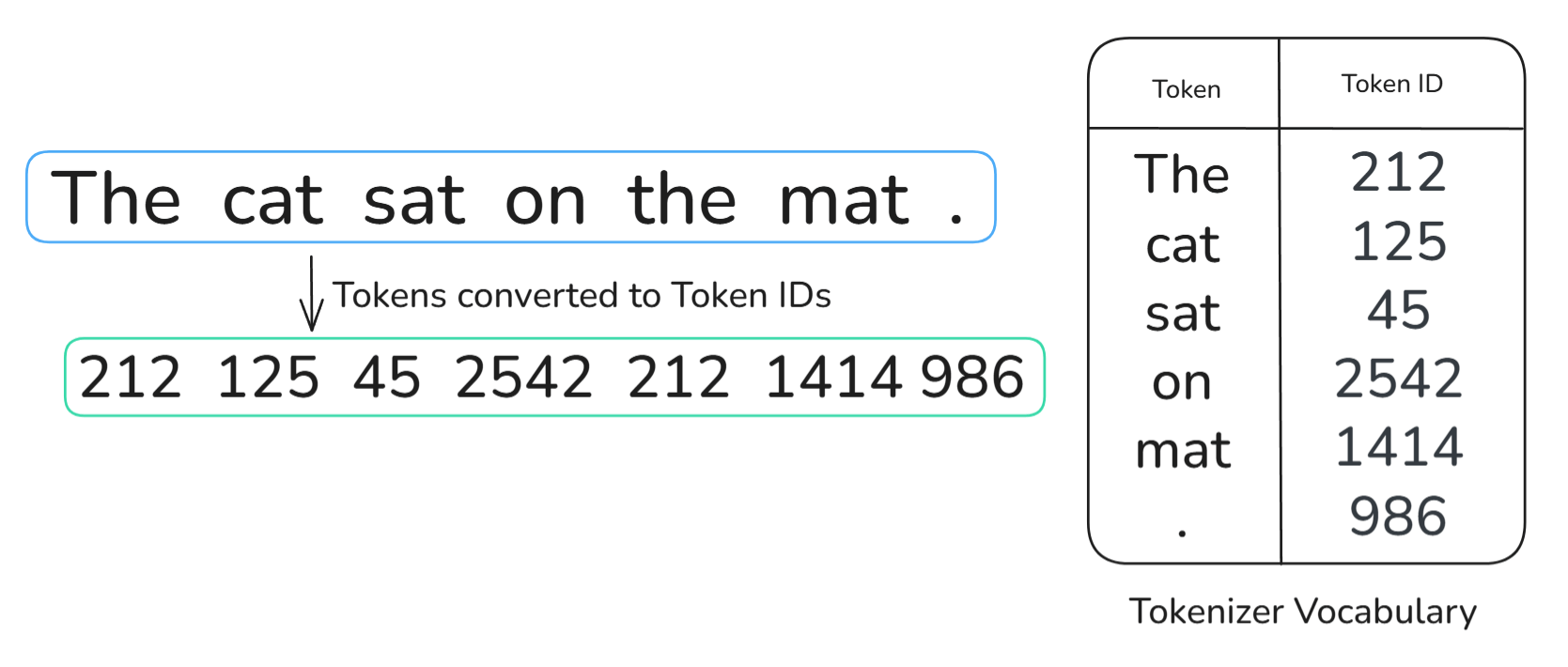
接着,每个唯一的 Token ID 会通过嵌入矩阵(embedding matrix)映射到其对应的 token 嵌入(token embedding)。需要注意的是,所有这些 token 嵌入都是相同维度的向量;在我们的例子中,假设维度为 512。
最后一步是添加位置嵌入(positional embedding),以便模型获得每个 token 的位置信息。常见的两种方法是:
- 正弦位置编码(Sinusoidal encoding,原始 Transformer 使用)
- 可学习的位置嵌入(Learned position embeddings,BERT、GPT 使用)
这些位置嵌入的具体机制超出了本文的范围。我们现在只需知道,最终的输入向量是通过以下公式得到的:
查询、键和值(Q, K, V)
现在我们终于可以介绍 Q、K、V 向量了。首先要注意的是,对于输入中的每个词,我们会创建三个向量:
- 查询(Query, Q) – 表示这个词在“寻找”什么
- 键(Key, K) – 表示这个词能“提供”什么给其他词
- 值(Value, V) – 表示这个词实际“携带”的信息
这些都是可学习的线性变换,也对应各自的矩阵。数学上,这些变换可表示为:
由此,每个 token 都可以用三个新向量来表示。下图有助于可视化这一过程:
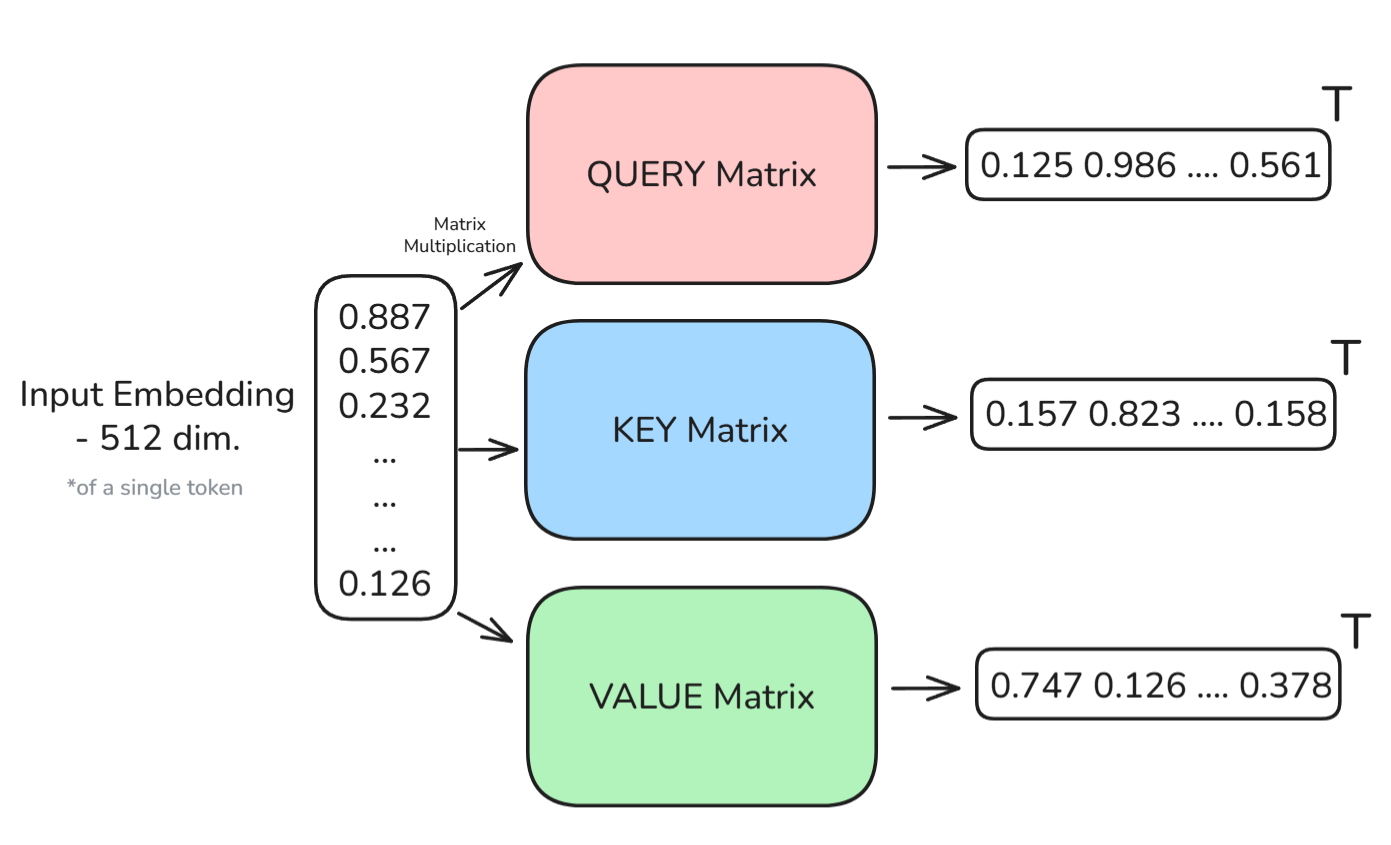 图示:每个输入 token 经过线性变换后生成 Q、K、V 三个向量
图示:每个输入 token 经过线性变换后生成 Q、K、V 三个向量
计算缩放点积注意力(Scaled Dot-Product Attention)
在《Attention is All You Need》论文中,给出了一个数学公式,展示了如何使用这些新向量计算注意力权重。让我们一步步走一遍,假设我们正在计算 “sat” 的注意力权重:
论文中给出的公式如下:
首先,我们使用 “sat” 的 Query 向量与所有其他词(包括它自己)的 Key 向量进行点积比较。结果是一组相似度分数(标量),告诉我们每个词与 “sat” 的相关程度。这些分数更正式地称为注意力分数(Attention Scores)。
然后,这些分数通过除以 进行缩放,以防止分数过大,并在反向传播训练时帮助稳定梯度。缩放后的分数再通过 softmax 函数,转化为注意力权重(Attention Weights)。
Softmax 给出一个概率分布,告诉模型每个词应赋予多少权重,因此某个 token 的所有注意力权重之和为 1。
最后,我们对 Value 向量进行加权求和,权重即为上述注意力权重。
这样就得到了一个新向量,它代表了上下文中的 “sat”,融合了所有 token 的信息,但主要来自 “cat”、“mat” 以及其他相关词。
这个过程会对句子中的每个 token都执行一次。每个 token 都会关注其他所有 token,甚至包括自己。这就是为什么我们称之为自注意力(self-attention)。
还要注意,我们刚才只计算了一个 token 的增强向量,但在实际操作中,我们会一次性对多个甚至所有 token 进行计算,因为矩阵乘法效率极高。
这之所以可行,是因为该架构完全可并行化。与按顺序处理的循环神经网络(RNN)不同,Transformer 能够一次性处理所有 token,使其既快速又强大。
图示:输入矩阵 X 被转换为 Q、K、V 矩阵,然后应用缩放点积注意力公式,得到所有 token 的增强嵌入向量 A
在 PyTorch 中实现缩放点积注意力
现在,让我们用 PyTorch 编写刚才讨论的内容。令人惊讶的是,它其实非常简单:
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V):
d_k = Q.size(-1) # key 向量的维度
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, V)
return output, attn_weights
通过实现一个简单的函数,我们就能复现上述讨论!以下是几个关键点:
- Q、K、V 是形状为
[batch_size, seq_len, dim]的张量 - 输出是一组新的向量,其中每个 token 都在其整个序列上下文中被表示
- 注意力分数(Attention Scores) 是未经归一化的原始相似度
- 注意力权重(Attention Weights) 是通过 softmax 归一化的,总和为 1
不同类型的注意力
不过,还有一个重要细节我尚未提及:Transformer 中并非只有一种注意力,实际上有三种:
- 编码器自注意力(Encoder self-attention)
- 解码器自注意力(Decoder self-attention)
- 编码器-解码器交叉注意力(Encoder–decoder (cross) attention)
每种注意力的作用略有不同,下面我们快速过一遍。
编码器自注意力
这就是我们目前为止所探讨的内容:在编码器中,每个 token 都会关注同一输入序列中的所有其他 token,例如 “the cat sat on the mat”。
关键在于,没有限制,因为整个输入是预先已知的,模型可以构建每个 token 的深度上下文表示,理解其前后的所有内容。
请注意,这发生在编码器中。
解码器自注意力
这里情况稍复杂一些。由于我们现在处于解码器中,我们不希望每个 token 能看到未来的信息,否则在文本生成时就“作弊”了。
再举个例子:“The dog barked very loudly.”(狗叫得非常大声。)当模型生成 “barked” 时(为简化,假设每个词是一个 token),它不应该知道下一个 token 是 “very”,否则模型就无法真正学会生成新词。
为解决这个问题,我们应用一个因果掩码(causal mask)(有时也称为三角掩码),确保每个 token 只能关注自身及之前的 token,绝不能关注未来的 token。
从上图可见,未来的注意力分数被掩码屏蔽,使模型能够学习生成新的、准确且合理的 token。
编码器-解码器交叉注意力
一旦解码器开始生成,它仍然需要原始输入的信息(即它要回应的内容)。这就是交叉注意力的作用。
在这里,解码器关注编码器的输出。因此,虽然解码器自注意力是带掩码的,但交叉注意力不带掩码,允许解码器一次性查看所有编码器 token。
当我学习这个概念时,非常喜欢翻译的例子:假设你要把 “Bonjour tout le monde” 翻译成英文,解码器在决定每个英文词时,应该能够看到所有的法语词,对吧?
这正是交叉注意力所做的。不过,由于超出本文范围,我们不再深入讨论交叉注意力。
为什么需要多头注意力?
现在我们理解了自注意力的工作原理。但你可能会问:
既然已经有了注意力,为什么还需要多个“头”?
对此,我想分享一个对我建立直觉非常有帮助的手电筒类比。
想象单个注意力头就像一支手电筒,试图照亮句子中的重要部分。但一个句子包含多种不同类型的关系需要理解:主谓关系、宾语-代词、形容词-名词、长距离依赖等。
如果每次只能捕捉一种关系,难道不是一种浪费吗?
因此,更好的解决方案是给模型多支手电筒,每支聚焦句子的不同部分。这就是多头注意力(Multi-Head Attention)。
我们不再只计算一组 Q、K、V 并运行一次注意力计算,而是将嵌入向量拆分成更小的部分,并行运行多个独立的注意力头。
如上图所示,输入嵌入(为简化,以单个 token 为例)被均匀拆分到 n 个不同的头中。
在我们的例子中,假设维度为 512,头数为 8,那么每个注意力头将并行处理 维,尝试捕捉不同的关系。
为了进一步建立直觉(注意:我们仍不完全清楚每个头具体关注什么关系),让我们看一个简单例子:
考虑这句话:
“The quick brown fox jumps over the lazy dog.”
- 一个头可能关注形容词-名词对:“quick → fox”,“lazy → dog”
- 另一个头可能关注主谓关系:“fox → jumps”
- 还有一个头可能捕捉长距离依赖:“jumps → over → dog”
关键在于,所有这些头同时运行,它们的输出会被拼接起来,并通过一个投影层映射回原始嵌入维度(本例中为 512)。
通过代码可视化多头注意力
为了彻底巩固对多头注意力的理解,我们使用 HuggingFace 库来观察多头注意力机制的实际运作。
!pip install transformers bertviz torch
首先运行上述代码安装所需包。
from transformers import BertTokenizer, BertModel
from bertviz import head_view
import torch
model_name = 'bert-base-uncased' # 我们将使用 BERT 模型
model = BertModel.from_pretrained(model_name, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_name)
model.eval() # 因为不训练,设为评估模式,避免参数更新
# 输入句子
sentence = "The quick brown fox jumps over the lazy dog."
# 使用分词器将句子转为 tokens
inputs = tokenizer(sentence, return_tensors='pt')
input_ids = inputs['input_ids']
# 前向传播并获取注意力
with torch.no_grad():
outputs = model(**inputs)
attentions = outputs.attentions # 元组形式:(num_layers, batch, num_heads, seq_len, seq_len)
# 将 token ID 转回 token
tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
# 可视化
head_view(attentions, tokens)
运行后,你会看到如下输出。注意有 12 种不同颜色,表示该模型有 12 个注意力头。线条的粗细也反映了 token 之间注意力分数的大小。
多头注意力的实现:最佳实践
在本节中,我们将编写多头注意力机制的伪代码。假设输入 的形状为 [batch, seq_len, d_model]。
伪代码如下:
Q = X @ W_Q # 计算 Query
K = X @ W_K # 计算 Key
V = X @ W_V # 计算 Value
Q_i, K_i, V_i = split_into_heads(Q, K, V, num_heads) # 将 Q, K, V 拆分为多个头(均匀拆分维度)
# 对每个头计算缩放点积注意力
scores = (Q_i @ K_i.T) / sqrt(head_dim)
scores += mask # 如需掩码(如因果掩码)
A_i = softmax(scores)
A_i = dropout(A_i)
Z_i = A_i @ V_i
Z = concat_heads(Z_i) # 拼接所有头的输出
# 最终线性投影
output = Z @ W_O
output = dropout(output)
以上内容你应该已经熟悉,除了最后的线性投影矩阵。
我们快速回顾一下:
所有独立的注意力头完成工作后,它们的输出会被拼接成一个向量。但这个组合输出仍需重塑回原始模型维度,这就是最终线性投影矩阵 的作用。它将拼接后的输出映射回与输入嵌入相同的尺寸,以便传递给 Transformer 的下一层。
我们还可以讨论一些优化和最佳实践:
- 并行化:由于每个头相互独立,可以全部并行计算。
- 矩阵乘法:我们使用线性代数运算(如 matmul)批量处理,高度优化。
- FlashAttention(高级):这是一种新技术,利用底层 CUDA 技巧减少内存开销并加速注意力计算,尤其适用于长序列。
在编写注意力层时,有三个主要超参数需要注意:
num_heads:并行运行的注意力头数量,必须能整除d_modelhead_dim:每个头的维度dropout_rate:用于防止过拟合
结论
本文内容丰富。我们从一个简单的想法出发:注意力就是聚焦。接着,我们探索了 Transformer 如何利用这种聚焦能力,通过 Query、Key 和 Value 计算每个词与其他所有词的关系。
我们看到了自注意力(以及简要提及的因果注意力和交叉注意力)如何为每个 token 提供丰富、上下文感知的表示。然后,我们更进一步,引入了多头注意力:与其依赖一支“手电筒”,不如给模型多支,每支同时捕捉句子中的不同模式。
这正是 Transformer 真正强大的原因。它们不只是“读取”文本,而是理解整个序列中的底层结构、含义和关系。