Jakob Jenkov 2021-03-08
并发系统可以使用不同的并发模型来实现。并发模型规定了系统中的线程如何协作以完成分配给它们的任务。不同的并发模型以不同的方式拆分任务,线程之间也可能以不同的方式进行通信与协作。
本教程将深入探讨当前(2015–2019 年)最流行的几种并发模型。
并发模型与分布式系统的相似性
本文描述的并发模型与分布式系统中使用的不同架构非常相似。在并发系统中,不同线程彼此通信;而在分布式系统中,不同进程(可能运行在不同计算机上)相互通信。从本质上讲,线程和进程非常相似,因此不同的并发模型通常看起来也类似于不同的分布式系统架构。
当然,分布式系统还面临额外的挑战,比如网络可能中断、远程计算机或进程宕机等。但在大型服务器上运行的并发系统也可能遇到类似问题,例如 CPU 故障、网卡故障、磁盘损坏等。虽然发生故障的概率较低,但理论上仍有可能。
正因为并发模型与分布式系统架构相似,它们常常可以互相借鉴思路。例如,将工作分配给多个工作者(线程)的模型,通常与分布式系统中的负载均衡模型类似。日志记录、故障转移、任务幂等性等错误处理技术也是如此。
共享状态 vs. 独立状态
并发模型的一个重要方面是:组件和线程是否设计为共享状态,还是拥有彼此独立、永不共享的状态。
共享状态 指的是系统中的不同线程共享某些数据(通常是一个或多个对象)。当线程共享状态时,可能会出现 竞态条件(race conditions) 和 死锁(deadlock) 等问题,具体取决于线程如何使用和访问这些共享对象。
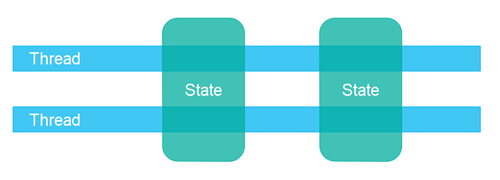
独立状态 意味着系统中的不同线程不共享任何状态。如果需要通信,它们通过交换不可变对象,或发送对象(或数据)的副本来实现。这样,只要没有两个线程同时写入同一个对象(数据/状态),就可以避免大多数常见的并发问题。
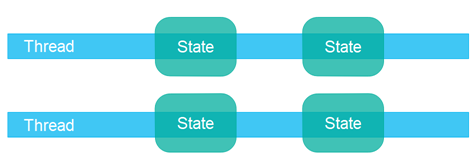
采用独立状态的并发设计通常会使部分代码更容易实现和推理,因为你清楚地知道只有一个线程会写入某个特定对象,无需担心对该对象的并发访问。不过,在整体应用架构层面,你可能需要更深入地思考如何采用独立状态模型。但在我看来,这种努力是值得的——我个人更倾向于使用独立状态的并发设计。
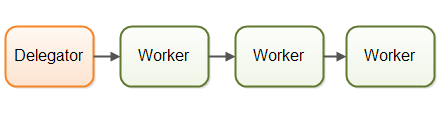
并行工作者模型(Parallel Workers)
第一种并发模型是我称之为 “并行工作者” 的模型。传入的任务被分配给不同的工作者。下图展示了该模型:
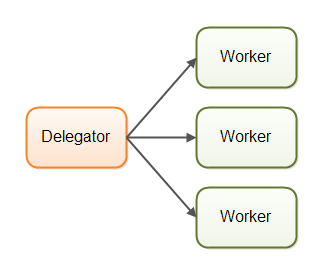
在此模型中,一个分发器(delegator) 将传入的任务分配给不同的工作者。每个工作者独立完成整个任务。这些工作者并行运行于不同的线程中,可能运行在不同的 CPU 上。
如果用汽车工厂来类比,并行工作者模型意味着每辆汽车由一名工人从头到尾制造。该工人拿到汽车规格后,独自完成全部组装工作。
并行工作者模型 是 Java 应用中最常用的并发模型(尽管这一情况正在改变)。Java 的 java.util.concurrent 包中的许多并发工具就是为此模型设计的。Java EE 应用服务器的设计中也能看到该模型的影子。
该模型既可以采用共享状态,也可以采用独立状态,即工作者要么能访问某些共享数据,要么完全不共享状态。
并行工作者模型的优点
- 易于理解:要提高应用程序的并行度,只需增加更多工作者。
- 可扩展性强:例如,若实现一个网页爬虫,你可以尝试用不同数量的工作者爬取一定数量的页面,观察哪种配置总耗时最短(即性能最高)。由于网页爬取属于 I/O 密集型任务,通常每个 CPU 核心配置几个线程效果最佳(一个线程往往因等待 I/O 而大量空闲)。
并行工作者模型的缺点
尽管表面简单,并行工作者模型存在一些潜在缺点。
共享状态可能导致复杂性
如果工作者需要访问某种共享数据(无论是内存中还是数据库中),正确管理并发访问会变得非常复杂。下图展示了共享状态如何使该模型复杂化:
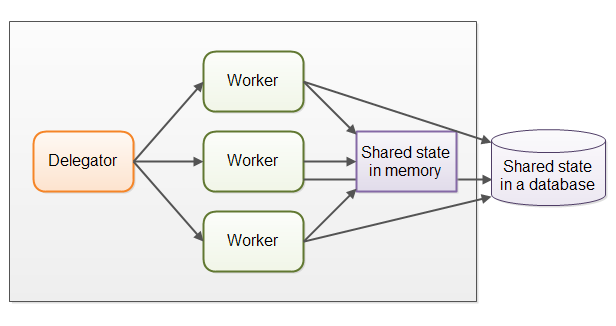
部分共享状态存在于通信机制(如任务队列)中,但也有不少是业务数据、缓存、数据库连接池等。
一旦共享状态引入并行工作者模型,系统就会变得复杂:
- 线程必须确保对共享数据的修改对其他线程可见(需写回主内存,而非停留在 CPU 缓存中);
- 必须避免 竞态条件、死锁 等问题;
- 当线程因访问共享数据结构而相互等待时,并行性会部分丧失;
- 许多并发数据结构是阻塞的,即同一时间只允许一个或有限数量的线程访问,这会导致争用(contention),严重时甚至使代码执行串行化,完全丧失并行优势。
现代的 无锁并发算法(non-blocking concurrency algorithms) 可减少争用、提升性能,但其实现难度很高。
持久化数据结构(Persistent Data Structures) 是另一种选择。它在修改时总是保留旧版本。因此,若多个线程引用同一持久化结构,其中一个线程修改后获得新版本引用,其他线程仍持有旧版本,数据保持一致。Scala 标准库就包含多种持久化数据结构。
然而,持久化数据结构性能通常不佳。例如,持久化列表通常在头部添加新元素,并返回新头部的引用。其他线程仍引用旧头部,看不到新元素。这种基于链表的实现无法充分利用现代 CPU 的缓存局部性(数据分散在内存各处),远不如基于数组的列表高效(CPU 缓存可批量加载连续数据)。
无状态工作者(Stateless Workers)
共享状态可能被其他线程修改,因此工作者每次使用状态时都必须重新读取,以确保使用最新数据——无论状态存储在内存还是外部数据库中。这种不保存内部状态、每次按需读取的工作者称为 无状态工作者。
频繁重新读取数据(尤其是来自外部数据库)可能很慢。
任务执行顺序不确定(Job Ordering is Nondeterministic)
并行工作者模型无法保证任务的执行顺序。任务 A 可能在任务 B 之前分配给工作者,但 B 可能先执行完。
这种不确定性使得难以推断系统在任意时刻的状态,也难以保证某个任务一定在另一个任务之前完成(尽管这并非总是问题,取决于系统需求)。
流水线模型(Assembly Line)
第二种并发模型是我称之为 “流水线” 的模型(名称仅为与“并行工作者”对应)。其他开发者根据平台/社区习惯,也可能称其为 响应式系统(Reactive Systems) 或 事件驱动系统(Event Driven Systems)。下图展示了该模型:
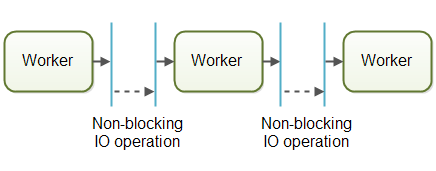
工作者像工厂流水线上的工人一样组织:每个工作者只完成整个任务的一部分,完成后将任务传递给下一个工作者。
采用流水线模型的系统通常设计为使用 非阻塞 I/O(Non-blocking IO)。这意味着当工作者发起 I/O 操作(如读取文件或网络数据)时,不会等待操作完成(因为 I/O 很慢),而是立即释放 CPU 去处理其他任务。当 I/O 完成后,结果会被传递给下一个工作者继续处理。
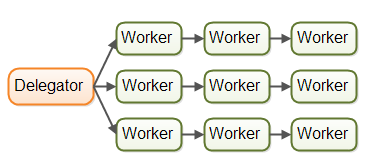
实际上,任务流并不总是沿单一生产线流动。由于系统通常同时处理多个任务,任务会根据下一步需要执行的操作,在不同工作者之间动态流转。真实情况可能如下图所示:
任务甚至可能被同时转发给多个工作者进行并发处理。例如,一个任务可能同时发送给执行器和日志记录器。下图展示了三条流水线最终都将任务交给同一个工作者(中间流水线的最后一个):
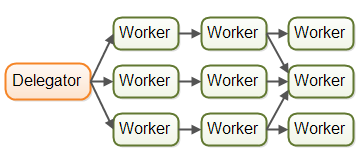
流水线结构可能比这更复杂。
响应式 / 事件驱动系统(Reactive, Event Driven Systems)
使用流水线模型的系统有时也被称为 响应式系统 或 事件驱动系统。系统中的工作者对系统内发生的事件做出反应——这些事件可能来自外部(如 HTTP 请求),也可能由其他工作者触发(如文件加载完成)。
目前(写作时)有许多有趣的响应式/事件驱动平台,且未来还会更多。较流行的包括:
- Vert.x
- Akka
- Node.js(JavaScript)
我个人对 Vert.x 非常感兴趣(尤其对于我这样的 Java/JVM “老古董”而言)。
Actor 模型 vs. Channel 模型(Actors vs. Channels)
Actor 和 Channel 是两种类似的流水线(或响应式/事件驱动)模型。
Actor 模型:每个工作者称为一个 Actor。Actor 可直接向彼此发送消息,消息异步发送和处理。可用于实现一条或多条任务处理流水线。
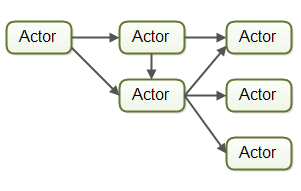
Channel 模型:工作者不直接通信,而是将消息(事件)发布到不同的 Channel(通道) 上。其他工作者可监听这些通道,而发送者无需知道谁在监听。
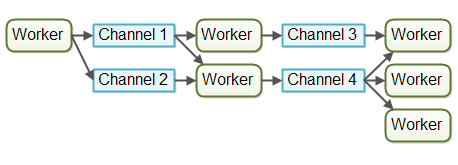
在我看来,Channel 模型更灵活:工作者只需知道将任务转发到哪个通道,无需了解后续由谁处理。监听者可自由订阅/取消订阅,不影响写入者,从而实现更松耦合。
流水线模型的优点
相比并行工作者模型,流水线模型具有多项优势。
无共享状态(No Shared State)
工作者之间不共享状态,因此无需考虑并发访问共享状态带来的各种问题,实现更简单——可像单线程一样编写工作者代码。
有状态工作者(Stateful Workers)
由于没有其他线程会修改其数据,工作者可以是有状态的(stateful),即将所需数据保留在内存中,仅在必要时写回外部存储。有状态工作者通常比无状态工作者更快。
更好地契合硬件特性(Better Hardware Conformity)
单线程代码通常更符合底层硬件的工作方式:
- 在单线程假设下,可设计出更优化的数据结构和算法;
- 有状态工作者可将数据缓存在内存中,进而更可能被 CPU 缓存命中,访问速度更快。
这种代码设计方式被称为 硬件契合(Hardware Conformity)(有些开发者称为 “机械同理心 Mechanical Sympathy”,但我认为“契合”更准确,毕竟计算机几乎没有机械部件)。
可保证任务顺序(Job Ordering is Possible)
流水线模型可设计为保证任务顺序。有序执行使系统状态更易推理。此外,还可将所有传入任务写入日志,用于在系统故障时重建状态——任务按日志顺序执行即可。
实现有序执行虽不易,但通常可行。一旦实现,备份、恢复、复制等操作均可通过日志完成,极大简化系统运维。
流水线模型的缺点
主要缺点是:单个任务的执行分散在多个工作者(即多个类)中,难以直观看出某个任务到底执行了哪些代码。
此外,编码可能更困难。工作者代码常以回调函数(callback handlers) 形式编写。过多嵌套回调会导致所谓 “回调地狱(Callback Hell)” ——难以跟踪代码逻辑,也难以确保每个回调都能访问所需数据。
相比之下,并行工作者模型的代码通常更易阅读:打开一个工作者类,基本可从头到尾理解其执行流程(尽管也可能跨多个类,但执行顺序更清晰)。
函数式并行(Functional Parallelism)
第三种并发模型是近年来(2015 年左右)备受关注的 函数式并行。
其核心思想是:使用函数调用实现程序。函数可视为彼此发送消息的“代理”或“Actor”(类似于流水线模型)。一个函数调用另一个函数,相当于发送消息。
传递给函数的所有参数都是副本,因此函数外部实体无法修改这些数据。这种复制机制可避免共享数据上的竞态条件,使函数执行类似于原子操作。每个函数调用可独立于其他调用执行。
既然每个函数调用可独立执行,那么它们就可以在不同 CPU 上并行运行。因此,以函数式方式实现的算法天然支持并行。
- Java 7 引入了
java.util.concurrent.ForkJoinPool,可用于实现类似函数式并行; - Java 8 引入了并行流(parallel streams),可并行迭代大型集合。
注意:部分开发者对
ForkJoinPool持批评态度(详见我的ForkJoinPool教程中的相关链接)。
函数式并行的难点在于:如何判断哪些函数调用值得并行化。跨 CPU 协调函数调用存在开销,只有当函数完成的工作量足够大时,并行才有意义。若函数调用本身很小,并行反而比单线程更慢。
据我理解,使用响应式/事件驱动模型也可实现类似函数式并行的任务分解,且能更精确地控制并行粒度。
此外,若系统同时运行多个任务(如 Web 服务器、数据库服务器等),则没有必要将单个任务强行并行化——其他 CPU 核心已在处理其他任务。此时,流水线(响应式)模型因开销更低、更契合硬件特性,通常是更好的选择。
哪种并发模型最好?
答案一如既往:视情况而定。
- 如果你的任务天然并行、彼此独立、无需共享状态,并行工作者模型可能合适。
- 但多数任务并非如此。对于这类系统,我认为 流水线模型 优势更明显,缺点更少,整体优于并行工作者模型。
你甚至无需自己实现流水线基础设施。现代平台如 Vert.x 已为你封装了大部分功能。就我个人而言,下一个项目我会探索基于 Vert.x 等平台的设计——Java EE 已不再具备优势。