Jakob Jenkov 2021-12-09
当两个或多个线程同时尝试访问同一个受保护的数据结构时,就可能发生线程拥塞(Thread Congestion)。
这里的“受保护”是指该数据结构通过 synchronized 块、并发工具类(如 Lock、BlockingQueue 等)进行了线程安全控制。
由此产生的线程拥塞意味着:试图访问共享数据结构的线程会花费大量时间排队等待访问权限——宝贵的执行时间被白白浪费在了等待上。
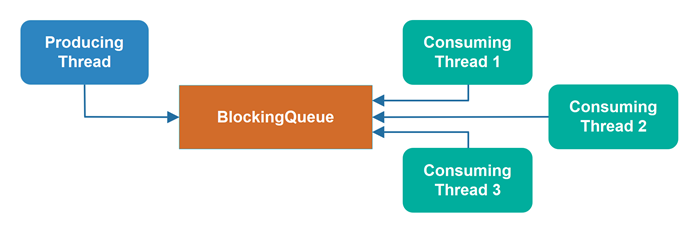
阻塞型数据结构可能导致线程拥塞
如果某个数据结构在特定条件下会阻塞试图访问它的线程(例如,当其他线程正在访问时),那么就可能引发线程拥塞。
当多个线程同时访问这样的数据结构时,一个或多个线程可能会被排队等待。
这种排队行为在代码中是不可见的,它发生在 Java 虚拟机内部。因此,仅靠阅读代码很难发现线程拥塞问题。你可能需要借助性能分析工具来检测,或者学会预测哪些地方容易发生拥塞。
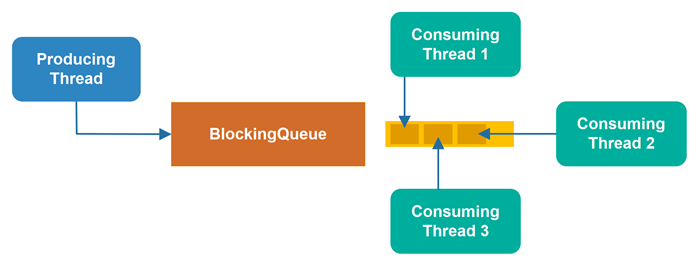
被阻塞的线程会损失执行时间
当一个线程因尝试访问阻塞型数据结构而被阻塞时,它无法执行任何其他任务。
因此,在被阻塞期间,线程会损失潜在的执行时间。阻塞时间越长,损失就越大。
线程越多,拥塞越严重
试图同时访问同一个共享阻塞型数据结构的线程数量越多,发生线程拥塞的可能性就越高,且拥塞程度(即排队等待的线程数量)也可能越严重。
缓解线程拥塞的方法
要缓解线程拥塞,核心思路是减少同时尝试访问同一阻塞数据结构的线程数量。以下是几种常用方法:
使用多个数据结构
以阻塞队列为例,一种有效策略是为每个消费者线程分配独立的队列,由生产者线程将任务分发到这些队列中。
这样,每个队列最多只有两个线程在访问:一个生产者线程和一个消费者线程,从而大幅降低竞争和拥塞。

使用无锁并发算法(Non-blocking Concurrency Algorithms)
另一种方法是采用 无锁并发算法,在这种算法中,线程访问数据结构时永远不会被阻塞。
相比阻塞式并发结构,无锁算法通常能更高效地利用线程的执行时间,减少等待开销。